آشنایی با الگوریتم خوشه بندی
جدول محتوایی
- مفاهیم پایه و اصلی در الگوریتم خوشه
- طبقهبندی کلی الگوریتمها و معیارهای طراحی خوشه بندی
- الگوریتمهای خوشه بندی پراستفاده: روشها و سازوکارها
- الگوریتمهای خوشه ای مبتنی بر چگالی و ساختار
- الگوریتمهای پیشرفته و مدلبنیان
- ارزیابی، مسائل عملی و دستورالعمل انتخاب الگوریتم خوشه ای درست
- معیارهای عددی و تصویری: Silhouette, Davies-Bouldin, Calinski-Harabasz
- نکات مهندسی در الگوریتم های خوشه بندی
- کاربردها و مطالعات آشنایی با الگوریتم خوشه بندی
- چکلیست عملی الگوریتم های خوشه بندی برای اجرا در پروژهها
- سخن آخر
اگر دادههای فراوانی به شما داده باشند، چطور میتوانید از بین انبوه دادههای بدون برچسب، گروههایی معنادار استخراج کنید؟ آشنایی با الگوریتم خوشه بندی پاسخ این سوال است. مجموعهای از روشها که دادهها را بر اساس تشابه یا ساختار پنهان به خوشههای همگن تقسیم میکنند.
قرار است در این مقاله، ابتدا مفاهیم پایه و انواع روشهای خوشهبندی را یاد بگیرید. پس از آن به کمک پرکاربردترین الگوریتمها، از K-Means تا DBSCAN و Spectral، معیارهای ارزیابی کیفیت خوشهها و نکات عملی پیادهسازی میآموزید. در نهایت با بررسی مطالعات موردی و چکلیست عملی برای انتخاب الگوریتم مناسب خواهید آموخت کجا و چطور از الگوریتمهای خوشه بندی استفاده کنید.
مفاهیم پایه و اصلی در الگوریتم خوشه
خوشهبندی فرایندی است برای گروهبندی خودکار نمونهها یا مشاهدات. این گروهبندی بهگونهای است که اعضای هر گروه یا همان خوشه بیشترین شباهت را به یکدیگر و کمترین شباهت را به اعضای خوشههای دیگر داشته باشند.
برخلاف طبقهبندی (classification) که به برچسبهای از پیش تعریفشده و دادههای برچسبخورده نیاز دارد، خوشهبندی روشی بدون ناظر (unsupervised) است و میخواهد ساختار پنهان یا الگوهای دروندادهای را کشف کند. بهعبارت دیگر، خوشهبندی ابزار کاوشی است که ساختار، زیرگروهها یا توزیعهای متفاوت در مجموعهداده را روشن میکند. ابزاری که اغلب پیشپردازشی ارزشمندی برای تحلیلهای بعدی فراهم میآورد.
در سطح مفهومی، چند ویژگی کلیدی برای درک خوشهبندی وجود دارد.
- تعریف معیار تشابه یا فاصله: مانند فاصله اقلیدسی، فاصله منهتن یا معیارهای مبتنی بر شباهت قطع مشترک
- انتخاب الگوریتم یا خانواده الگوریتمها: مثلا روشهای تفکیکگر/مرکزی، سلسلهمراتبی، مبتنی بر چگالی یا مدلبنیان
- تعیین پارامترهای عملیاتی: شامل تعداد خوشهها، آستانه چگالی یا تعداد مولفهها در مدلها.
- انتخاب مقیاس و پیشپردازش داده: شامل استانداردسازی، حذف ویژگیهای بیارزش یا کاهش ابعاد
خوشهبندی را میتوان در حوزههای مختلف از تقسیمبندی مشتریان در بازاریابی، کشف ساختار در دادههای زیستی، فشردهسازی تصویر تا کشف ناهنجاریها به کار برد.

طبقهبندی کلی الگوریتمها و معیارهای طراحی خوشه بندی
الگوریتمهای خوشهبندی را میتوان از دیدگاه نحوه شکلگیری و تفسیر «خوشهها» به چند خانواده اصلی تقسیم کرد. هر خانواده، منطق خاصی برای تعریف شباهت و جداسازی گروهها دارد و به همین دلیل در شرایط متفاوت عملکردهای متمایزی خواهند داشت. این دستهبندی نهتنها از نظر مفهومی بلکه برای انتخاب الگوریتم مناسب در پروژههای واقعی اهمیت دارد، زیرا نوع داده، اندازه نمونه، شکل توزیع و وجود نویز در دادهها بر انتخاب روش تأثیرگذارند. بهطور کلی چهار معیار اصلی طراحی در خوشهبندی مطرح است.
- پایهگذاری هندسی یا آماری الگوریتم: آیا خوشهها بهصورت کرهای و همگن فرض میشوند یا از مدلهای آماری استفاده میشود؟
- نوع معیار شباهت یا فاصله: که مبنای تعلق نقاط به خوشههاست.
- الگوی رشد خوشهها: فزایشی، تقسیمگر، یا مبتنی بر چگالی.
- نیاز یا عدم نیاز به تعداد خوشه از پیش تعیینشده.
برای آنکه با هر یک از این معیارها بیشتر آشنا شوید، در بخشهای بعد آنها را به تفکیک مرور میکنیم تا درک روشنی از تفاوت ساختاری میان آنها ایجاد شود.
معیارهای تمایز الگوریتمها؛ مرکزی، سلسلهمراتبی، چگالیمحور و مدلبنیان
الگوریتمهای خوشهبندی از نظر نحوه گروهبندی دادهها و معیار تمایز خوشهها با یکدیگر تفاوت دارند. برخی بر اساس فاصله تا مرکز خوشه، برخی بر پایه سلسلهمراتب، برخی براساس چگالی و برخی دیگر با مدلسازی آماری عمل میکنند. درک این تمایز به انتخاب الگوریتم مناسب برای دادهها و مسئلهی مورد نظر کمک خواهد کرد.
- الگوریتمهای مرکزی (Partitioning Methods): این روشها مانند K-Means دادهها را در چند خوشه مجزا تقسیم میکنند و هر خوشه با مرکز ثقل (centroid) مشخص میشود. سادگی و سرعت بالا از مزایای آنهاست، اما به شکل کروی داده حساساند.
- الگوریتمهای سلسلهمراتبی (Hierarchical Methods): دادهها را در سطوح مختلف تجمیع یا تفکیک میکنند و ساختار درختی (دندروگرام) ایجاد میشود. این رویکرد برای کشف خوشههای تو در تو مناسب است اما هزینه محاسباتی بیشتری دارد.
- الگوریتمهای چگالیمحور (Density-Based): نظیر DBSCAN، نقاط متراکم را در یک خوشه قرار میدهند و نواحی کمتراکم را نویز تلقی میکنند. این گروه در شناسایی خوشههای غیرکروی و با اندازههای مختلف عملکرد بهتری دارند.
- الگوریتمهای مدلبنیان (Model-Based): مانند Gaussian Mixture Model (GMM) با فرض توزیع آماری خاص، دادهها را مدلسازی میکنند و احتمال تعلق هر نقطه به هر خوشه را میسنجند. این روشها تحلیلیتر و قابل تفسیرترند، اما به انتخاب مدل مناسب وابستهاند.
با بررسی این چهار خانواده، میفهمید که انتخاب الگوریتم خوشهبندی نه تنها به ساختار دادهها بستگی دارد، بلکه به هدف تحلیل و محدودیتهای عملی نیز وابسته است.
الگوریتمهای خوشه بندی پراستفاده: روشها و سازوکارها
در میان انواع الگوریتم خوشه بندی (clustering algorithm)، برخی به دلیل سادگی، پایداری و قابلیت پیادهسازی گستردهتر، به استانداردهای صنعتی و آموزشی تبدیل شدهاند. مهمترین نمونهها شامل خانوادهی K-Means و نسخههای بهینهشده آن است. این الگوریتمها بر پایه تقسیم دادهها به خوشههای با میانگین کمترین فاصله تعریف میشوند. چنین روشهایی بهویژه برای دادههای عددی و بزرگمقیاس، عملکرد مطلوبی دارند و به همین دلیل در ابزارهایی مانند Scikit-learn، TensorFlow و SPSS بهصورت پیشفرض گنجانده شدهاند.
در کنار آن الگوریتمهای مبتنی بر مراکز ثقل فرض میکنند که هر خوشه ساختاری تقریبا کروی دارد. در نتیجه، هنگامی که دادهها دارای شکلهای نامنظم یا نویز بالا باشند، این فرض دقت خوشهبندی را کاهش خواهد داد. با این حال، بهواسطه سرعت بالا و سادگی ریاضی، K-Means همچنان در تحلیلهای اکتشافی، پیشپردازش داده و تعیین برچسبهای اولیه برای روشهای پیچیدهتر مورد استفاده قرار میگیرد.
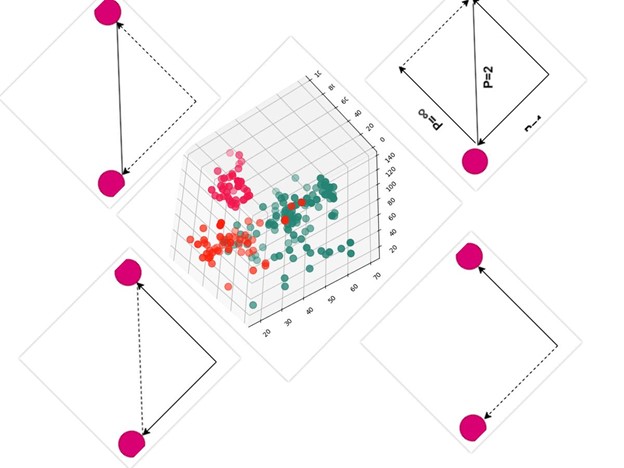
الگوریتمهای خوشه ای مبتنی بر چگالی و ساختار
الگوریتمهای مبتنی بر چگالی و ساختار، خوشهها را بر اساس تراکم نقاط در فضای ویژگی تعریف میکنند. بر خلاف روشهای مرکزی مانند K-Means که فرض خوشههای کروی دارند، این خانواده خوشههای با شکل نامنظم و اندازه متفاوت را شناسایی کرده و نقاط نویز (outliers) را از خوشهها جدا میکند. مزیت اصلی این رویکرد، توانایی تشخیص ساختارهای پیچیده و مقاوم بودن نسبت به نویز است، مخصوصا اگر دادهها واقعی اما تراکم متغیر باشند.
در ادامه این بخش شما را با DBSCAN، OPTICS و HDBSCAN آشنا میکنیم تا تفاوتها و کاربردهای هر الگوریتم را بشناسید. نکته کلیدی این است که هر الگوریتم، اگرچه بر اساس چگالی عمل میکند، اما استراتژی و نحوه استخراج خوشهها متفاوت است و برای سناریوهای مختلف دادهای بهینهسازی میشود.
الگوریتم های DBSCAN
DBSCAN یا Density-Based Spatial Clustering of Applications with Noise یک الگوریتم کلاسیک چگالیمحور است که خوشهها را از طریق هستههای چگال شناسایی میکند. هر نقطهای که تعداد همسایگانش در شعاع eps برابر یا بیشتر از minPts باشد، به عنوان هسته شناخته میشود. خوشهها با گسترش از این هستهها شکل میگیرند و نقاطی که به هیچ خوشهای متصل نشوند، به عنوان نویز طبقهبندی میشوند. کاربردهای این الگوریتم را در زیر نام بردهایم.
- شناسایی مناطق پرجمعیت در نقشههای جغرافیایی
- تشخیص ناهنجاریهای تراکنش مالی
- بخشبندی مشتریان با الگوهای رفتار متنوع
این الگوریتم به دلیل عدم نیاز به تعیین تعداد خوشهها از پیش و مقاومت بالا نسبت به نویز، برای دادههای واقعی و پیچیده بسیار مناسب است. با این حال، DBSCAN برای دادههایی با چگالی متغیر محدودیت دارد و ممکن است خوشهها را به درستی تفکیک نکند. در این موارد الگوریتمهای پیشرفتهتر مانند OPTICS یا HDBSCAN توصیه میشوند.
الگوریتم OPTICS
OPTICS از عبارت Ordering Points To Identify the Clustering Structure میآید. این الگوریتم یک توسعه از DBSCAN است که به جای یک مقدار eps ثابت، ساختار چگالی دادهها را در طیفی از تراکمها تحلیل میکند. این الگوریتم ابتدا نقاط داده را بر اساس دسترسی (reachability) مرتب کرده و نمودار reachability را تولید میکند تا خوشهها در سطوح مختلف چگالی شناسایی شوند.
مزیت اصلی OPTICS، توانایی تشخیص خوشهها با چگالی متغیر است. کاربردهای رایج آن شامل:
- تحلیل شبکههای اجتماعی
- خوشهبندی اسناد متنی
- پردازش تصویر
است. برای مثال، در تحلیل شبکههای حمل و نقل شهری، OPTICS مناطق پرتردد و کمتردد را به صورت سلسلهمراتبی تشخیص میدهد و نقاط پرت یا نویز را جدا میکند.
الگوریتم HDBSCAN
HDBSCAN توسعهای از DBSCAN و مفاهیم سلسلهمراتبی است که بهصورت خودکار خوشههای پایدار را از دادههای با چگالی متفاوت استخراج میکند. ابتدا درخت چگالی ساخته شده و سپس خوشههای پایدار با تحلیل سلسلهمراتبی انتخاب میشوند.
این الگوریتم مزیتهای DBSCAN را حفظ میکند، اما نیاز به تعیین eps ندارد و به جای آن خوشههای با چگالی متغیر را بهتر شناسایی میکند. همچنین HDBSCAN قادر است soft clustering انجام دهد، یعنی درجه تعلق نقاط به خوشهها را ارائه دهد که در تحلیلهای پیچیده و تصمیمگیریهای حساس به عدم قطعیت مفید است.
در عمل، HDBSCAN در کتابخانه hdbscan پایتون پیادهسازی میشود و با ساختمان دادههای بهینه مانند KD-Tree سرعت آن افزایش مییابد. این الگوریتم برای دادههای بزرگ و پرنویز گزینهای حرفهای و قدرتمند به شمار میآید.
الگوریتمهای پیشرفته و مدلبنیان
در مقابل روشهای مبتنی بر فاصله یا چگالی، الگوریتمهای مدلبنیان سعی میکنند ساختار داده را با فرض یک مدل آماری یا ماتریسی توصیف کنند. این رویکردها برای دادههای پیچیده، پیوسته یا دارای ساختار درونی مناسبترند. با این الگوریتمها در زیر آشنا میشوید.
- Gaussian Mixture Model: الگوریتم GMM فرض میکند دادهها از ترکیبی از چند توزیع نرمال چندبعدی تشکیل شدهاند. هر خوشه با یک مؤلفه گاوسی مشخص میشود و پارامترهای آن شامل؛ میانگین، کوواریانس، وزنها با الگوریتم Expectation-Maximization برآورد میشوند.
- Spectral Clustering: بر پایه نظریه طیفی گراف است. ابتدا گراف شباهت بین دادهها ساخته میشود، سپس ماتریس لاپلاسین نرمالشده محاسبه و بردارهای ویژه آن استخراج میشوند. Spectral Clustering قادر است ساختارهای غیرکروی و بسیار پیچیده را کشف کند و برای دادههای تصویری، شبکهای و اجتماعی بسیار مؤثر است.
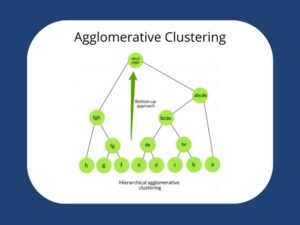
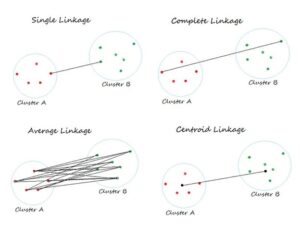
- Agglomerative (Hierarchical) Clustering: از پایین به بالا شروع میکند و در هر گام نزدیکترین خوشهها را ادغام میکند تا سلسلهمراتبی از خوشهها بسازد. مزیت آن در انعطاف در انتخاب معیار شباهت (linkage) و امکان دیدن ساختار در سطوح مختلف است و در دادههای با اندازه متوسط و ساختار تو در تو کاربرد دارد.
نکته این است که شما به یاد داشته باشید، این روشها زمانی انتخاب میشوند که توزیع دادهها پیچیده، ابعاد بالا یا مرز خوشهها مبهم باشد. به عبارت دیگر جایی که روشهایی چون K-means یا DBSCAN از دقت کافی برخوردار نباشند.
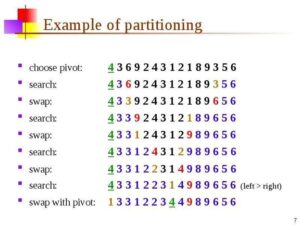
ارزیابی، مسائل عملی و دستورالعمل انتخاب الگوریتم خوشه ای درست
انتخاب و ارزیابی یک الگوریتم خوشهبندی (clustering algorithm) فرایندی چند بعدی است که باید هم از جنبه عددی و هم از نظر کاربردی بررسی شود. برخلاف روشهای نظارتشده، در خوشهبندی برچسب واقعی دادهها در دسترس نیست، بنابراین ارزیابی کیفیت خوشهها بر اساس معیارهای درونی (Internal Metrics) و تحلیل بصری انجام میشود.
- در ارزیابی درونی، ساختار داده با خود مدل مقایسه میشود؛ یعنی بررسی میشود که اعضای هر خوشه تا چه حد به هم شبیه و از دیگر خوشهها متمایز هستند.
- در مقابل، در ارزیابی بیرونی (External Validation) که در صورت وجود برچسبهای مرجع انجام میشود، تطابق خوشهها با دستههای واقعی سنجیده میشود. برای مثال با معیار Adjusted Rand Index
در کنار این معیارها، تحلیل تصویری دادهها در فضاهای دوبعدی کمک میکند تا ساختار خوشهها بهصورت شهودی مشاهده شود.
حال مهم این است که بدانید انتخاب الگوریتم مناسب نیز به ماهیت داده بستگی دارد. مثلا در دادههای دارای نویز زیاد الگوریتم های خوشه بندی DBSCAN یا HDBSCAN بهتر عمل میکنند. همچنین در دادههای همپوشان با الگوریتم Gaussian Mixture Model نتایج بهتر هستند و دادههای ساده و کرویشکل با K-means بهتر تحلیل میشوند. در نهایت باید بگوییم در عمل، هیچ الگوریتمی بهطور جهانشمول برتر نیست؛ بلکه باید با معیارهای ارزیابی و قیاس تجربی انتخاب شود.
معیارهای عددی و تصویری: Silhouette, Davies-Bouldin, Calinski-Harabasz
ارزیابی کیفیت خوشهبندی یکی از مراحل کلیدی در تحلیل دادههای بدون برچسب است. استفاده از معیارهای عددی و تصویری به شما کمک میکند تا تصمیم بگیرید کدام الگوریتم و تنظیمات پارامتری، بهترین جدایی و انسجام خوشهها را ارائه میدهد. در ادامه سه شاخص عددی پرکاربرد و روشهای ارزیابی بصری معرفی شدهاند.
- Silhouette Coefficient: میانگین تفاوت بین میانگین فاصله درونخوشهای و نزدیکترین خوشه مجاور را میسنجد. مقدار نزدیک به 1 نشاندهنده خوشههای متراکم و مجزا است، در حالیکه مقادیر منفی نشاندهنده اشتباه در تخصیص خوشههاست.
- Davies–Bouldin Index (DBI): نسبت مجموع پراکندگی درونخوشهای به جدایی بین خوشهها را محاسبه میکند. هرچه مقدار DBI کمتر باشد، خوشهبندی بهتر است.
- Calinski–Harabasz Index (CH): بر اساس نسبت بین واریانس بینخوشهای به درونخوشهای تعریف میشود. مقادیر بالاتر نشاندهنده تفکیک بهتر خوشهها هستند.
علاوهبر معیارهای عددی، ارزیابی بصری با روشهایی مانند PCA، t-SNE یا UMAP جدایی خوشهها را در فضای 2 یا 3 بعدی نشان میدهد. این روش به خصوص برای دادههای پیچیده و پرابعاد مفید است. همچنین ترکیب تحلیل عددی و بصری، تصمیمگیری برای انتخاب الگوریتم نهایی را بهینه میکند.
به طور مثال پس از اجرای HDBSCAN روی دادههای مشتریان، ترسیم نقاط با UMAP کمک میکند تا خوشههای شناسایی شده به صورت بصری نیز از یکدیگر تفکیک شوند و نقاط نویز قابل شناسایی باشند.
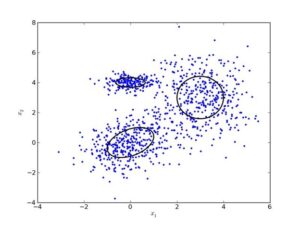
نکات مهندسی در الگوریتم های خوشه بندی
در اجرای عملی الگوریتمهای خوشهبندی، جزئیات فنی نقش مهمی در دقت و پایداری نتایج دارند. این جزئیات را در زیر برایتان آوردهایم.
- مقیاسگذاری (Scaling): دادهها باید نرمالسازی یا استاندارد شوند، زیرا الگوریتمهایی مانند K-means و GMM به واحد اندازهگیری حساساند.
- کاهش ابعاد: استفاده از PCA یا Autoencoder پیش از خوشهبندی نویز را کاهش میدهد و ساختار اصلی داده را نمایان میکند.
- مقداردهی اولیه: انتخاب نقاط اولیه مناسب مثلا در K-means++ از گیر افتادن در مینیمم محلی جلوگیری میکند.
- پیچیدگی محاسباتی: برخی الگوریتمها مانند Spectral یا Agglomerative در دادههای بزرگ مقیاسپذیری کمی دارند. در چنین شرایطی روشهای تقریبی یا Mini-Batch پیشنهاد میشوند.
رعایت این نکات نهتنها کیفیت خوشهبندی را بهبود میدهد، بلکه امکان تکرارپذیری و تفسیرپذیری نتایج را نیز افزایش میدهد.
کاربردها و مطالعات آشنایی با الگوریتم خوشه بندی
الگوریتمهای خوشهبندی (clustering algorithms) امروز در هسته بسیاری از سامانههای هوشمند قرار دارند. از تحلیل رفتار کاربران گرفته تا پردازش تصویر و تشخیص ناهنجاری از این الگوریتمها استفاده میشود. برای آنکه با این کاربردها آشنا شوید در ادامه چند مثال واقعی را برایتان آوردهایم.
- بازاریابی و تقسیمبندی مشتریان: شرکتهای بزرگ از خوشهبندی برای تفکیک مشتریان بر اساس رفتار خرید، موقعیت جغرافیایی یا الگوهای مصرف استفاده میکنند. برای مثال، در پلتفرمهای خردهفروشی مانند Amazon، مدلهایی نظیر K-means یا GMM برای شناسایی گروههای مشتری با علایق مشابه به کار میروند و مبنای شخصیسازی پیشنهادها را تشکیل میدهند.
- تحلیل تصویر و بینایی ماشین: در بینایی ماشین، الگوریتمهایی چون Spectral Clustering و Agglomerative برای تفکیک اشیاء در تصاویر یا گروهبندی ویژگیهای استخراجشده از شبکههای عصبی به کار میروند. برای نمونه، در تشخیص سلولهای سرطانی در میکروسکوپ نوری، خوشهبندی رنگ و بافت به تفکیک نواحی غیرعادی کمک میکند.
- شناسایی ناهنجاری (Anomaly Detection): روشهایی مانند DBSCAN و HDBSCAN قادرند نقاط دورافتاده یا رفتارهای غیرعادی را در دادههای مالی، صنعتی و امنیتی شناسایی کنند. سیستمهای کشف تقلب بانکی یا تشخیص نفوذ در شبکههای سایبری، از این رویکرد برای تشخیص الگوهای غیرطبیعی بهره میبرند.
در مجموع، قدرت خوشهبندی در یافتن ساختار دادهها، بدون نیاز به برچسب یا نظارت پنهان بوده و همین ویژگی آن را به ابزاری کلیدی در تصمیمگیری دادهمحور تبدیل کرده است.
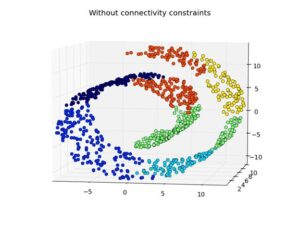
چکلیست عملی الگوریتم های خوشه بندی برای اجرا در پروژهها
برای استفاده مؤثر از الگوریتمهای خوشهبندی در پروژههای واقعی، پیروی از یک روند گامبهگام ضروری است. چکلیست زیر یک مسیر استاندارد و قابلاجرا ارائه میدهد:
- آمادهسازی داده: دادهها را پاکسازی و نرمالسازی کنید. کارهایی شامل رفع مقادیر گمشده، حذف نویز، مقیاسگذاری ویژگیها. اگر ابعاد زیاد بود از PCA یا UMAP برای کاهش بعد استفاده کنید.
- انتخاب متریک شباهت: برای دادههای عددی از Euclidean یا Manhattan Distance و برای برای دادههای متنی یا دوحالته از Cosine یا Jaccard Similarity استفاده کنید.
- انتخاب الگوریتم مناسب: در مرحله بعد به سراغ الگوریتم انتخاب کردن بروید. اگر دادههای شما کروی و ساده هستند با K-means پیش بروید. اگر داده پرنویز یا با شکل نامنظم دارید DBSCAN / HDBSCAN را انتخاب کنید. اگر دادههای دارای همپوشانی آماری بودند، الگوریتم GMM بهترین گزینه است. در دادههای گرافی یا شبکهای نیز بهترین الگوریتم Spectral خواهد بود.
- انتخاب معیار ارزیابی نتایج: به طور مثال میتوانید از معیارهایی مانند Silhouette و Davies–Bouldin برای مقایسه مدلها بهره ببرید و خروجی را با مصورسازی دوبعدی بررسی کنید تا جدایی خوشهها ملموس شود.
- استنتاج و تصمیمگیری کسبوکار: نتایج خوشهبندی را به بخشهای قابلاجرا تبدیل کنید. مثلا تعریف پرسونای مشتری یا تعیین نواحی پرریسک.
این روند، چارچوبی سیستماتیک برای اجرای موفق خوشهبندی از مرحله داده خام تا نتیجه عملی فراهم میکند.
سخن آخر
تا به اینجا چیزی بیشتر از آشنایی با الگوریتم خوشه بندی به شکل ساده یاد گرفتهاید. با خواندن این مقاله با مفاهیم و انواع الگوریتم خوشهبندی (clustering algorithm) آشنا شدید. از روشهای پایهای مانند K-means تا مدلهای پیچیدهتر نظیر DBSCAN، GMM و Spectral Clustering را حال میشناسید. همچنین آموختید که ارزیابی نتایج با شاخصهایی مانند Silhouette و Calinski–Harabasz تصمیمگیری درباره کیفیت مدل را بهینه میسازد.
همچنین حالا دیگر میدانید که خوشهبندی نهتنها ابزاری برای گروهبندی دادهها، بلکه روشی برای کشف الگوهای پنهان در دنیایی از دادههای خام است. در بازاریابی، پزشکی، امنیت سایبری و تحلیل تصاویر، این الگوریتمها به سازمانها کمک میکنند تا تصمیمهای دقیقتر و مبتنی بر داده بگیرند.
اگر به دنبال درک عمیقتر از کاربردهای هوش مصنوعی در کسبوکار یا دادهکاوی هستید، پیشنهاد میشود مقالههای دیگر دربارهی یادگیری بدون نظارت را نیز در سایت چابکاِی مطالعه کنید.
سوالات متداول
مقالات مشابه

برنامه نویسی با هوش مصنوعی
1404/10/14
18 دقیقه

رشته هوش مصنوعی
1404/10/09
18 دقیقه

ایمیل مارکتینگ با هوش مصنوعی
1404/10/07
23 دقیقه

بازار کار هوش مصنوعی
1404/09/30
18 دقیقه

google colab چیست؟
1404/09/27
18 دقیقه
ساخت بازی کامپیوتری با هوش مصنوعی
1404/09/25
14 دقیقه

تولید محتوا با هوش مصنوعی
1404/09/23
25 دقیقه

آشنایی با ابزارهای هوش مصنوعی Google Cloud AI
1404/09/18
24 دقیقه

راهنمای جامع و کاربردی هوش مصنوعی و تحلیل رقبا
1404/09/11
17 دقیقه

آشنایی با ابزارهای هوش مصنوعی Metabase
1404/09/09
17 دقیقه

هوش مصنوعی با MATLAB: از تحلیل داده تا ساخت مدلهای پیشرفته
1404/09/06
25 دقیقه
دانلود اپلیکیشن
ارتقا سطح دانش و مهارت و کیفیت سبک زندگی با استفاده از هوش مصنوعی یک فرصت استثنایی برای انسان هاست.
ثبت دیدگاه
نظری موجود نمیباشد