مدل پیشبینی کننده (Predictive model) چیست؟
جدول محتوایی
- چکیدهای برای کاربران عادی درباره مدلهای پیشبینیکننده در هوش مصنوعی
- مقدمه
- منظور از مدل پیشبینی کننده (Predictive Model) چیست؟
- انواع مدلهای پیشبینی کننده
- اجزای اصلی مدل پیشبینی کننده (Predictive Model)
- روشهای رایج برای پیشبینی داده کدامند؟
- الگوریتمهای محبوب برای پیشبینی داده
- نحوه عملکرد مدل پیشبینیکننده چگونه است؟
- کاربردهای مدل پیشبینیکننده
- مزایای استفاده از مدل پیشبینیکننده
- معایب استفاده از مدل پیشبینی کننده
- نحوه ساخت مدل پیشبینی کننده
- انواع روشهای ساخت مدل پیشبینی کننده
- سخن آخر
چکیدهای برای کاربران عادی درباره مدلهای پیشبینیکننده در هوش مصنوعی
حتماً دیدهاید که چطور هواشناسی پیشبینی میکند که فردا باران میبارد یا مثلاً چطور یک اپلیکیشن خرید آنلاین حدس میزند شما چه محصولاتی را دوست دارید. پشت این پیشبینیها، چیزی به نام “مدلهای پیشبینیکننده” قرار دارد. این مدلها با بررسی دادههای گذشته، الگوها و روابطی را پیدا میکنند که به کمک آنها میتوانند رفتارها و اتفاقات آینده را پیشبینی کنند. در واقع، این ابزارها شبیه یک نقشه هستند که مسیرهای آینده را برای ما روشن میکنند.
مدلهای پیشبینیکننده در هوش مصنوعی، مثل یک تحلیلگر حرفهای عمل میکنند. آنها دادهها را جمعآوری کرده، الگوهای پنهان را پیدا میکنند و با استفاده از ریاضیات و الگوریتمها، آینده را تخمین میزنند. برای مثال، این مدلها میتوانند در پزشکی برای پیشبینی بیماریها، در حملونقل برای کاهش ترافیک، یا در بازاریابی دیجیتال برای تحلیل رفتار مشتریان استفاده شوند. حتی وقتی اپلیکیشنهایی مثل نتفلیکس فیلمی را پیشنهاد میدهند، از همین مدلها کمک میگیرند.
چیزی که این مدلها را خاص میکند، تواناییشان در درک پیچیدگیها و ارتباطات میان دادههاست. با یادگیری مداوم، آنها هوشمندتر میشوند و به کمکشان میتوان تصمیمات بهتر و دقیقتری گرفت. از خرید ساده گرفته تا تصمیمات بزرگ اقتصادی یا پزشکی، مدلهای پیشبینیکننده به ما کمک میکنند زندگی را کمی راحتتر و دقیقتر برنامهریزی کنیم.

مقدمه
به احتمال زیاد شما هم تاکنون در اخبار یا منابع مختلف، پیشبینیهای متفاوتی در رابطه با شرایط آب و هوایی، وضعیت اقتصاد و موارد مشابه دیگر ملاحظه کردهاید. ممکن است از خود بپرسید که سازمانها و شرکتها چگونه میتوانند تا این اندازه پیش بینیهای دقیقی داشته باشند؟ جواب این سوال در یک راهحل ویژه به نام مدل پیشبینی کننده (Predictive model) نهفته است. در واقع این ابزارها یکی از بهترین و ایده آلترین نوآوریهای بشر است که میتواند بر اساس اطلاعات گذشته، بخش قابل توجهی از دادههای مربوط به آینده را برای ما پیشبینی کند. اما بسیاری از مردم نمیدانند که مدل پیشبینی کننده (Predictive model) چیست؟ چگونه عمل میکند؟ یا چطور میتوان یک مدل پیش بینی کننده ساخت؟ این موارد همگی سوالهایی هستند که ما میکوشیم تا در ادامه این مقاله آنها را زیر ذره بین نقد و بررسی خود قرار داده و تمام جنبههایش را خدمت شما عزیزان بیان کنیم. لذا اگر تمایل دارید تا در این رابطه اطلاعات بیشتری کسب کنید، حتماً ما را تا انتها همراهی فرمایید.
منظور از مدل پیشبینی کننده (Predictive Model) چیست؟
تصور کنید در حال تماشای یک جاده طولانی هستید؛ جادهای که هر پیچ و خم آن داستانی از گذشته را روایت میکند و در عین حال، نقشهای از آینده را هم ترسیم میکند. مدل پیشبینیکننده دقیقاً همانند این جاده عمل میکند؛ یعنی با تحلیل و تفسیر مسیرهای گذشته، در تلاش است تا آینده را پیشبینی نماید. این ابزار هوشمند، قلب بسیاری از تصمیمات مدرن شناخته میشود که به کمک دادهها و الگوهای گذشته، دیدگاهی روشن از آنچه در پیش روی ماست، ارائه میدهد.
مدل پیشبینیکننده، در واقع یک چارچوب ریاضیاتی و الگوریتمی است که بر مبنای دادههای تاریخی و روندهای مشاهده شده عمل میکند. این مدلها به مجموعهای از ابزارها و روشها وابسته هستند که شامل تحلیلهای آماری، الگوریتمهای یادگیری ماشین، و گاهی ترکیبی از این دو است. هدف اصلی این مدلها، شناسایی الگوهای تکرارشونده و روابط پنهان در دادههاست تا بتواند رویدادهای آینده را با دقت بالایی پیشبینی کند. در این فرآیند، دادههای ورودی به عنوان مواد خام عمل میکنند که پس از پردازش، به نقشهای جامع از رفتار احتمالی آینده تبدیل میشوند.
یکی از ویژگیهای برجسته مدلهای پیشبینیکننده، توانایی پاسخگویی به سناریوهای “چه میشد اگر” (What if) است. به عنوان مثال، این مدلها میتوانند به ما نشان دهند که اگر در گذشته تصمیم خاصی گرفته میشد، نتیجه میتوانست چگونه باشد. این ویژگی، مدلهای پیشبینیکننده را به ابزاری قدرتمند برای تحلیل تصمیمات گذشته و طراحی استراتژیهای بهتر برای آینده تبدیل کرده است. بنابراین، این مدل نه تنها به پیشبینی کمک میکند، بلکه با ایجاد درک عمیقتر از روابط پیچیده میان دادهها، راه را برای نوآوری و بهبود هموار میسازد. این موضوع در هوش مصنوعیهای مربوط به پیش بینیهای مالی بیشتر به چشم میخورد.

انواع مدلهای پیشبینی کننده
کارآمدی و جذابیت مدلهای پیشبینیکننده باعث شده است که در سالهای اخیر، متخصصان انواع مختلفی از این مدلها را طراحی کنند. با این حال، بیشتر این مدلها در دو گروه اصلی یعنی مدلهای نظارتشده (Supervised) و مدلهای بدون نظارت (Unsupervised) قرار میگیرند. ما در ادامه، این دو نوع را به شیوهای دقیق زیر ذره بین نقد و بررسی قرار داده ایم. در نظر داشته باشید که بسیاری از افراد ، مدلهای پیشبینی کننده را بر اساس شیوه ساخت مانند مدل طبقه بندی، مدل انحرافات، مدل عصبی و… دسته بندی میکنند. اما در نهایت همگی آنها زیر مجموعه دو گروه زیر خواهند بود.
مدلهای نظارتشده (Supervised Models)
مدلهای نظارتشده بر اساس دادههایی که دارای برچسب یا خروجی مشخصی هستند، آموزش میبینند. این مدلها با تحلیل رابطه میان ورودیها و خروجیها، میتوانند پیشبینی دقیقی از نتایج جدید ارائه دهند. به عنوان مثال، در یک فروشگاه آنلاین، از این مدلها میتوان برای پیشبینی احتمال خرید یک مشتری بر اساس رفتار گذشته او استفاده کرد. نمونه واضح آن پیامک ها و ایمیل های تخفیف کالاهایی است که از طرف فروشگاه های بزرگ مانند دیجی کالا یا آمازون برای مشتریان ارسال می شود.
یکی از روشهای رایج در این گروه، استفاده از الگوریتمهای یادگیری ماشین مانند رگرسیون خطی، شبکههای عصبی و درختهای تصمیم است. این تکنیکها به مدل کمک میکنند تا با دقت بیشتری الگوهای موجود در دادهها را شناسایی کرده و نتایج آینده را پیشبینی کند.
مدلهای بدون نظارت (Unsupervised Models)
در مدلهای بدون نظارت، دادهها فاقد برچسب یا خروجی مشخص هستند. این مدلها به جای پیشبینی، بیشتر بر کشف الگوهای پنهان یا گروهبندی دادهها تمرکز دارند. به عنوان مثال، در یک بانک میتوان از این مدلها برای شناسایی دستهبندی مشتریان بر اساس رفتار مالی آنها استفاده کرد.

اجزای اصلی مدل پیشبینی کننده (Predictive Model)
مدلهای پیشبینی کننده شامل مجموعهای از اجزای به هم پیوسته هستند که با همکاری یکدیگر، امکان تحلیل دادهها و پیشبینی رویدادهای آینده را فراهم میکنند. هر کدام از این اجزا نقشی حیاتی دارند و فهم آنها میتواند دیدگاه عمیقتری نسبت به نحوه عملکرد این مدلها ایجاد کند. در ادامه، اجزای کلیدی این مدلها را توضیح میدهیم.
1. دادهها (Data)
دادهها، شالوده هر مدل پیشبینی کننده هستند و بدون وجود دادههای دقیق و کامل، پیشبینی امکانپذیر نیست. این دادهها به سه بخش اصلی تقسیم میشوند:
دادههای آموزشی (Training Data): این دادهها برای یادگیری الگوها و روابط میان متغیرها توسط مدل استفاده میشوند.
دادههای اعتبارسنجی (Validation Data): برای تنظیم مدل و انتخاب بهترین پارامترها استفاده میشوند تا عملکرد آن بهینه شود.
دادههای آزمایشی (Test Data): برای ارزیابی نهایی دقت و عملکرد مدل به کار میروند.
لازم به ذکر است که هرچه کیفیت و گستردگی دادهها بیشتر باشد، مدل توانایی بیشتری در پیشبینی نتایج دقیق خواهد داشت.
2. ویژگیها (Features)
ویژگیها، متغیرهای ورودی هستند که اطلاعاتی درباره پدیده مورد بررسی ارائه میدهند. انتخاب ویژگیهای مناسب، فرآیندی به نام مهندسی ویژگی (Feature Engineering)، میتواند تاثیر چشمگیری بر عملکرد مدل داشته باشد.
به عنوان مثال، در پیشبینی رفتار مشتریان، ویژگیهایی مانند سابقه خرید، سن، و منطقه جغرافیایی میتوانند سرنخهای مهمی ارائه دهند. انتخاب نادرست ویژگیها ممکن است مدل را گمراه کند و دقت پیشبینیها کاهش یابد.
3. برچسبها (Labels)
برچسبها نتایج واقعی یا خروجیهای مورد انتظار هستند که مدل برای یادگیری و پیشبینی به آنها نیاز دارد.
در مدلهای رگرسیونی، برچسبها معمولاً مقادیر عددی هستند (مانند پیشبینی قیمت).
در مدلهای دستهبندی، برچسبها نماینده دستهها یا گروههای مختلف هستند (مانند تشخیص اینکه ایمیلی اسپم است یا خیر).
برچسبها نقش دستورالعمل را برای مدل بازی میکنند و به آن میگویند که چه چیزی باید پیشبینی شود.
4. الگوریتم پیشبینی (Predictive Algorithm)
الگوریتم پیشبینی، مغز متفکر مدل است. این الگوریتمها بر اساس دادهها، روابط و الگوهایی را کشف میکنند که برای پیشبینی استفاده میشوند. بسته به نوع مسئله، از الگوریتمهای مختلفی مانند رگرسیون، درختهای تصمیم، یا شبکههای عصبی استفاده میشود.
5. تابع هزینه (Loss Function)
این تابع، میزان خطای مدل را اندازهگیری میکند. هدف از آموزش مدل، کاهش مقدار این تابع است تا پیشبینیها دقیقتر شوند. مثلاً در مسائل رگرسیونی، از خطای میانگین مربعات (MSE) برای سنجش دقت مدل استفاده میشود.
6. اعتبارسنجی مدل (Model Validation)
اعتبارسنجی شامل تکنیکهایی مانند Cross-Validation است که به جلوگیری از بیشبرازش (Overfitting) کمک میکند. این فرآیند تضمین میکند که مدل نه تنها روی دادههای آموزشی خوب عمل کند، بلکه روی دادههای جدید نیز نتایج دقیقی ارائه دهد.

روشهای رایج برای پیشبینی داده کدامند؟
در دنیای تحلیل داده و پیشبینی، روشهای متعددی وجود دارند که هرکدام برای حل مسائل مختلف طراحی شدهاند. این روشها پایههای بسیاری از مدلهای پیشبینی مدرن را تشکیل میدهند. اما برخی از این روشها به دلیل کارایی و انعطافپذیری بیشتر، محبوبیت بیشتری یافتهاند. در ادامه، به پنج روش رایج در این زمینه میپردازیم.
1. درختهای تصمیم (Decision Trees)
درختهای تصمیم یکی از ابزارهای قدرتمند برای پیشبینی هستند که با ساختاری شبیه یک درخت، دادهها را تحلیل و دستهبندی میکنند. در این روش، هر شاخه نمایانگر یک تصمیم و هر برگ نشاندهنده یک نتیجه احتمالی است. از این روش میتوان برای مسائل دستهبندی (مانند تشخیص نوع مشتری) و مسائل عددی (مانند پیشبینی قیمت) استفاده کرد. یکی از مزایای اصلی درختهای تصمیم این است که خروجی آنها به راحتی قابل تفسیر است و میتوان روند تصمیمگیری مدل را دنبال کرد.
2. تحلیل سریهای زمانی (Time Series Analysis)
این روش برای پیشبینی وقایع بر اساس دادههایی که به ترتیب زمانی مرتب شدهاند، به کار میرود. تحلیل سریهای زمانی به شما امکان میدهد الگوها، ترندها و فصلی بودن دادهها را شناسایی کرده و از آنها برای پیشبینی آینده استفاده کنید. برای مثال، جهت پیشبینی فروش ماهانه یا تغییرات دمای هوا از این روش بهره میبرند. تکنیکهایی مانند مدل ARIMA یا تجزیه سریهای زمانی، ابزارهای اصلی در این حوزه هستند.
3. رگرسیون لجستیک (Logistic Regression)
رگرسیون لجستیک، یکی از روشهای پایهای در پیشبینی است که برای مسائل دستهبندی مانند “بله یا خیر” یا “اسپم یا غیر اسپم” استفاده میشود. این روش بر اساس مدلهای آماری کار میکند و احتمال رخداد یک رویداد را پیشبینی میکند. رگرسیون لجستیک به ویژه در مواردی که دادهها رابطه غیرخطی پیچیدهای ندارند، عملکرد بسیار خوبی دارد و به عنوان یکی از روشهای محبوب در مسائل طبقهبندی به شمار میرود.
4. شبکههای عصبی (Neural Networks)
شبکههای عصبی الهام گرفته از نحوه کارکرد مغز انسان طراحی شدهاند و برای شناسایی روابط پیچیده میان متغیرها بسیار مناسب هستند. این روش با لایههای متعدد از “نورونها”، دادهها را تحلیل و روابط بین آنها را شناسایی میکند. شبکههای عصبی برای مسائل پیچیدهای مانند تشخیص تصویر، پیشبینی رفتار کاربر یا تحلیل صدا بسیار کارآمد هستند. همچنین، این روش یکی از اصلیترین ابزارها در یادگیری ماشین و هوش مصنوعی محسوب میشود.
5. یادگیری تقویتی (Reinforcement Learning)
یادگیری تقویتی، روشی نوین برای پیشبینی است که در آن مدل از طریق تعامل با محیط خود و دریافت بازخورد، یاد میگیرد. این روش برای مسائلی که نیاز به تصمیمگیری پویا دارند، مانند بازیهای رایانهای یا مدیریت انرژی در سیستمهای هوشمند، بسیار کارآمد است. مزیت اصلی این روش، توانایی یادگیری مداوم و بهینهسازی تصمیمات بر اساس شرایط جدید است.

الگوریتمهای محبوب برای پیشبینی داده
حالا که با روشهای رایج پیشبینی دادهها آشنا شدهاید، وقت آن است که به سراغ الگوریتمهای معروف در این زمینه برویم. این الگوریتمها از روشهای پایه الهام گرفتهاند و به دلیل کارایی بالا و دقت مناسب، به عنوان ابزارهای اصلی در ساخت مدلهای پیشبینی شناخته میشوند. در ادامه با سه الگوریتم رایج و کاربردی آشنا میشوید که هرکدام برای حل مسائل خاصی طراحی شدهاند.
1. جنگل تصادفی (Random Forest)
جنگل تصادفی یک الگوریتم قوی است که با ترکیب چندین درخت تصمیم غیرمرتبط، پیشبینیهای دقیقی ارائه میدهد. ایده اصلی این روش این است که به جای اعتماد به یک درخت تصمیم، مجموعهای از آنها ایجاد و نتیجهگیری را بر اساس میانگین یا اکثریت نتایج انجام دهد. این تکنیک به کاهش احتمال بیشبرازش (Overfitting) کمک میکند و برای مسائل دستهبندی و رگرسیون بهخوبی عمل میکند.
2. مدل گرادیان تقویت شده (Gradient Boosted Model)
مدل گرادیان تقویت شده از درختهای تصمیم بهره میگیرد اما با یک تفاوت کلیدی: هر درخت جدید به نحوی طراحی میشود که خطاهای درخت قبلی را اصلاح کند. به بیان سادهتر، این روش به جای ساخت یک جنگل با درختهای مستقل، مجموعهای از درختها را به صورت متوالی ایجاد میکند که هرکدام پیشبینی دقیقتری نسبت به قبلی ارائه میدهند.
3. الگوریتم کیمیانگین (K-Means)
کیمیانگین یکی از الگوریتمهای محبوب خوشهبندی است که دادهها را به گروههای مشابه تقسیم میکند. این الگوریتم بهویژه برای مسائلی مناسب است که در آن نیاز به گروهبندی دادهها یا شناسایی الگوهای پنهان دارید. برای مثال، در حوزه فروشگاههای آنلاین، از کیمیانگین برای ارائه پیشنهادهای شخصیسازیشده به مشتریان استفاده میشود؛ به این صورت که مشتریان را بر اساس رفتار خرید یا ترجیحاتشان خوشهبندی میکند.
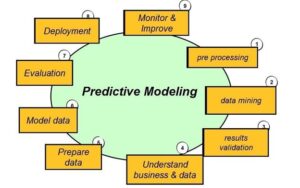
نحوه عملکرد مدل پیشبینیکننده چگونه است؟
یکی از سوالات رایجی که برای بسیاری از افراد پیش میآید این است که مدلهای پیشبینیکننده دقیقاً چگونه کار میکنند؟ این ابزارهای پیشرفته چگونه میتوانند از دادههای گذشته برای پیشبینی آینده استفاده کنند؟ پاسخ به این سوال میتواند به شما در درک بهتر این فناوری قدرتمند کمک کند.
عملکرد مدل پیشبینیکننده به این صورت است که ابتدا دادهها از منابع مختلف جمعآوری میشوند. این دادهها میتوانند شامل اطلاعات جمعیتشناسی و جغرافیایی، تاریخچه خرید، تعامل کاربران با وبسایت یا کمپینهای بازاریابی باشند. سپس دانشمندان داده با استفاده از این اطلاعات، مدل مناسبی را برای تحلیل انتخاب میکنند. انتخاب مدل مناسب نقش بسیار مهمی در دقت پیشبینیها دارد.
یکی از سادهترین مثالها برای نحوه عملکرد این مدلها، رگرسیون خطی است. در این مدل، دو متغیر مرتبط با هم (یکی وابسته و دیگری مستقل) بررسی میشوند. با استفاده از نمودارهای ساده، میتوان رابطه بین این دو متغیر را ترسیم کرد و بر اساس این رابطه، نتایج جدید را پیشبینی کرد. البته، مدلهای پیشرفتهتر، از روشهای پیچیدهتری بهره میبرند که شامل ترکیب الگوریتمهای مختلف برای ارائه پیشبینیهای دقیقتر میشود.
کاربردهای مدل پیشبینیکننده
مدلهای پیشبینیکننده، با وجود اینکه پیچیدگیهای زیادیشان، اما در بسیاری از حوزهها کاربرد دارند. برخلاف تصور برخی که این مدلها را تنها مختص مسائل تخصصی یا حوزههای خاص میدانند، باید گفت که تقریباً هر زمینهای که به تصمیمگیریهای آیندهنگرانه نیاز داشته باشد، میتواند از این مدلها بهره ببرد. در ادامه، با چند نمونه از کاربردهای متنوع این مدلها آشنا میشویم.
۱. کاربرد در پزشکی
مدلهای پیشبینیکننده نقش بسزایی در پزشکی دارند. از پیشبینی شیوع بیماریها گرفته تا تشخیص زودهنگام سرطان، این مدلها کمک میکنند که تصمیمات درمانی بهینهتر شوند. برای مثال، با تحلیل دادههای ژنتیکی و سوابق پزشکی بیماران، میتوان خطر ابتلا به بیماریهای مزمن را پیشبینی کرد و اقدامات پیشگیرانه انجام داد. همچنین، این ابزارها به مدیریت منابع بیمارستانی و کاهش هزینههای درمان کمک میکنند.
۲. کاربرد در اقتصاد
در حوزه اقتصاد، این مدلها برای پیشبینی روندهای بازار، مدیریت ریسک و تحلیل رفتارهای اقتصادی استفاده میشوند. مثلاً سرمایهگذاران با کمک این مدلها میتوانند تغییرات قیمت سهام را پیشبینی کنند و استراتژیهای خود را بر اساس آن تنظیم کنند. همچنین، دولتها از این مدلها برای پیشبینی نرخ تورم، رشد اقتصادی و نرخ بیکاری بهره میبرند تا سیاستگذاریهای مؤثرتری انجام دهند.
۳. کاربرد در مهندسی
مدلهای پیشبینیکننده در مهندسی نیز کاربرد گستردهای دارند. از پیشبینی زمان خرابی تجهیزات صنعتی گرفته تا بهینهسازی فرآیندهای تولید، در تمامی موارد، این مدلها بهرهوری را افزایش میدهند. به عنوان مثال، در صنایع خودروسازی، مدلهای پیشبینیکننده میتوانند زمان دقیق تعمیرات پیشگیرانه را پیشنهاد دهند و از توقفهای ناگهانی خطوط تولید جلوگیری کنند.
۴. کاربرد در علوم اجتماعی
علوم اجتماعی نیز از قدرت این مدلها برای تحلیل رفتارهای انسانی و اجتماعی بهره میبرند. مدلهای پیشبینیکننده میتوانند الگوهای مهاجرت، تغییرات جمعیتی و حتی رفتار رأیدهندگان در انتخابات را تحلیل کنند. این اطلاعات به سیاستگذاران کمک میکند تا برنامهریزیهای دقیقتری انجام دهند. همچنین، در مدیریت بحرانهای اجتماعی، مانند پیشبینی ناآرامیها یا اثرات بلایای طبیعی، این مدلها بسیار مؤثر هستند.
۵. کاربرد مدل های پیش بینی کننده در حمل و نقل
مدلهای پیشبینیکننده در حوزه حمل و نقل، برای بهبود تجربه سفر و کاهش هزینهها به کار گرفته میشوند. این مدلها میتوانند ترافیک را پیشبینی کرده و مسیرهای بهینه را پیشنهاد دهند. همچنین، در صنعت هوانوردی، از این مدلها برای پیشبینی نیاز به تعمیرات پیشگیرانه در هواپیماها استفاده میشود. شرکتهای حملونقل عمومی نیز با این مدلها میتوانند برنامهریزی دقیقتری برای زمانبندی سفرها داشته باشند.
۶. کاربرد در بازاریابی دیجیتال
مدلهای پیشبینیکننده یکی از ابزارهای اصلی بازاریابان دیجیتال محسوب میشوند. این مدلها با تحلیل رفتار کاربران، میتوانند بهترین زمان برای ارسال تبلیغات یا نوع محصولی که بیشترین احتمال خرید را دارد پیشبینی کنند. مدلهای پیشبینیکننده می توانند با بررسی فاکتورهای مختلفی از تاریخچه خرید مشتریان گرفته تا تعامل آنها با وبسایت، به بهینهسازی استراتژیهای بازاریابی کمک کرده و باعث افزایش فروش یا رضایت مشتریان شوند.
مزایای استفاده از مدل پیشبینیکننده
بهرهگیری از مدلهای پیشبینیکننده، به دلیل مزایای گستردهای که ارائه میدهند، به یکی از ابزارهای محبوب در صنایع مختلف تبدیل شده است. این مدلها علاوه بر بهبود تصمیمگیری، به سازمانها کمک میکنند تا منابع خود را بهینهتر استفاده کرده و به سودآوری بیشتری دست یابند. در ادامه، برخی از مهمترین مزایای استفاده از این مدلها را بررسی میکنیم.
۱. دقت و صحت بالا
مدلهای پیشبینیکننده با استفاده از الگوریتمهای یادگیری ماشین و تکنیکهای آماری پیشرفته، تحلیل دادهها را با دقت بسیار بالایی انجام میدهند. این ویژگی باعث میشود که تصمیمات بر اساس پیشبینیها، بسیار دقیق و قابل اعتماد باشند. در صنایعی مانند پزشکی یا مالی، این دقت بالا میتواند به معنای صرفهجویی در هزینهها یا حتی نجات جان انسانها باشد.
۲. تصمیمگیری آگاهانه مبتنی بر داده
یکی از مهمترین مزایای این مدلها، ارائه اطلاعات دقیق و قابل اعتماد برای تصمیمگیری است. این مدلها دادههای واقعی را تحلیل کرده و به جای اتکا به حدس و گمان یا تجربیات گذشته، چشمانداز دقیقی از آینده ارائه میدهند. این موضوع به سازمانها کمک میکند تا تصمیمات استراتژیک بهتری بگیرند.
۳. بهبود هدفگذاری در بازاریابی
مدلهای پیشبینیکننده به بازاریابان کمک میکنند تا مشتریان هدف را بهتر شناسایی نمایند. این ابزارها میتوانند رفتار مشتریان را تحلیل کرده و پیشنهادهایی ارائه دهند که متناسب با نیازهای خاص هر فرد باشد. این امر باعث میشود که کمپینهای بازاریابی نهتنها موفقتر باشند، بلکه هزینههای اضافی نیز کاهش یابد.
۴. تخصیص بهینه منابع
یکی از چالشهای اصلی در هر سازمان، مدیریت بهینه منابع است. مدلهای پیشبینیکننده میتوانند با تحلیل دادههای موجود، نیازهای آینده را پیشبینی کرده و منابع را به بهترین شکل ممکن تخصیص دهند. به عنوان مثال، یک کارخانه میتواند زمان تعمیرات پیشگیرانه را با دقت برنامهریزی کرده و از توقفهای ناگهانی جلوگیری کند.
۵. کاهش ریسک در استراتژیهای کسبوکار
با استفاده از مدلهای پیشبینیکننده، سازمانها میتوانند ریسکهای مرتبط با تصمیمات خود را به حداقل برسانند. این مدلها با تحلیل الگوهای بازار و رفتار مشتریان، تغییرات احتمالی را پیشبینی کرده و به سازمانها کمک میکنند تا برای چالشهای آینده آماده شوند.
۶. بهینهسازی کمپینهای بازاریابی
مدلهای پیشبینیکننده به بازاریابان این امکان را میدهند که کمپینهای خود را بهینهتر طراحی کنند. این مدلها میتوانند زمان و محتوای مناسب برای ارسال پیامهای تبلیغاتی را مشخص کرده و نرخ بازگشت سرمایه (ROI) را افزایش دهند. علاوه بر این، با تحلیل رفتار کاربران، میتوان کمپینها را شخصیسازی کرد و به نتایج بهتری دست یافت.
۷. بهبود حاشیه سود
یکی از بزرگترین مزایای این مدلها، افزایش سودآوری سازمانها است. با بهینهسازی فرآیندها، کاهش هزینهها و افزایش بهرهوری، این مدلها به کسبوکارها کمک میکنند تا با منابع موجود، بیشترین بازدهی را داشته باشند. این امر بهویژه در صنایعی مانند تجارت الکترونیک و تولیدات صنعتی، نقش کلیدی دارد.

معایب استفاده از مدل پیشبینی کننده
مدلهای پیشبینی کننده با وجود مزایای بالا، اما معایبی هم دارند که باید هنگام استفاده از آنها مورد توجه قرار گیرد. این معایب، ویژگیهای خاصی هستند که باعث میشوند استفاده از این مدلها در مقایسه با سایر روشها چالشبرانگیز باشد. اگرچه این معایب در برابر مزایای گسترده این ابزار به چشم نمیآیند، اما توجه به آنها میتواند دیدگاه شما را بهبود بخشد. در ادامه به تعدادی از این معایب پرداختهایم:
۱. وابستگی به دادههای دقیق و کامل
مدلهای پیشبینی کننده به شدت به دادههای ورودی وابسته هستند. کیفیت و دقت دادهها تأثیر مستقیمی بر صحت پیشبینیها دارند. اگر دادهها ناقص، نادرست یا قدیمی باشند، خروجی مدل میتواند کاملاً گمراهکننده باشد. این موضوع نه تنها باعث میشود تصمیمگیریها اشتباه باشند، بلکه ممکن است به ضررهای مالی یا کاهش اعتماد مشتریان منجر شود. بنابراین، فراهم کردن دادههای قابل اعتماد و متنوع، یکی از چالشهای اصلی در استفاده از این ابزار است.
۲. پیچیدگی فنی و نیاز به تخصص بالا
استفاده از مدلهای پیشبینی کننده، به دانش تخصصی در حوزههای تحلیل داده، یادگیری ماشین و آمار نیاز دارد. اگر تیم شما از مهارت و تجربه کافی برخوردار نباشد، ممکن است درک صحیحی از نحوه بهکارگیری این مدلها و تحلیل نتایج نداشته باشد. این موضوع میتواند باعث سوءاستفاده یا کاربرد نادرست از ابزار شود. همچنین، برای راهاندازی و مدیریت این مدلها معمولاً به سرمایهگذاری روی نیروی انسانی متخصص یا استفاده از خدمات مشاوران حرفهای نیاز است.
۳. ملاحظات قانونی و حریم خصوصی
مدلهای پیشبینی کننده معمولاً با استفاده از دادههای کاربران و مشتریان کار میکنند. جمعآوری و استفاده از این دادهها باید مطابق با قوانین حفظ حریم خصوصی و با رضایت کامل کاربران انجام شود. عدم رعایت این قوانین میتواند منجر به مشکلات قانونی و آسیب به شهرت کسبوکار شود. این محدودیتها گاهی باعث میشوند که دسترسی به برخی دادههای کلیدی دشوار باشد و توانایی مدل در ارائه پیشبینیهای دقیق کاهش یابد.
۴. نیاز به نظارت و بهروزرسانی مستمر
بازارها و رفتار مشتریان دائماً در حال تغییر هستند، بنابراین مدلهای پیشبینی کننده نیاز دارند که بهطور مستمر نظارت، تنظیم و بهینهسازی شوند. این فرآیند زمانبر بوده و منابع انسانی و مالی قابل توجهی را به خود اختصاص میدهد. اگر این نظارت و بهروزرسانی به درستی انجام نشود، مدل ممکن است به مرور زمان ناکارآمد یا غیرقابل اعتماد شود.

نحوه ساخت مدل پیشبینی کننده
تا اینجا با جذابیت و کارایی مدلهای پیشبینی کننده آشنا شدهاید و احتمالاً این سؤال برای شما پیش آمده که این مدلها چگونه ساخته میشوند. در حقیقت ساخت یک مدل پیشبینی کننده فرایندی چندمرحلهای است که دقت و برنامهریزی خاصی نیاز دارد. ما در ادامه، مراحل ساخت این مدلها را به زبانی ساده و روان توضیح دادهایم تا شما بتوانید با فرآیند آن آشنا شوید:
۱. تعریف مسئله (Problem Definition)
اولین قدم در ساخت مدل پیشبینی کننده، شناسایی و تعریف مسئله است. باید بدانید دقیقاً چه چیزی را میخواهید پیشبینی کنید و چرا باید آن را انجام دهید. این شامل شناسایی متغیر وابسته (نتیجه موردنظر) و متغیرهای مستقل (عوامل تأثیرگذار) است. تعریف شفاف مسئله به شما کمک میکند تا از همان ابتدا به سمت راهحلهای مناسب هدایت شوید. به عنوان مثال، آیا هدف شما پیشبینی میزان فروش ماهانه است یا پیشبینی رفتار مشتریان؟
۲. جمعآوری و آمادهسازی دادهها (Data Collection & Preparation)
دادهها قلب تپنده مدلهای پیشبینی کننده هستند. این دادهها میتوانند از منابع مختلفی مثل پایگاههای داده، سیستمهای CRM، یا حتی فایلهای Excel جمعآوری شوند. دادهها باید دقیق، بهروز و مرتبط با مسئله باشند. علاوه بر این، مرحله آمادهسازی شامل حذف نویز، تکمیل مقادیر گمشده و یکپارچهسازی منابع داده مختلف است. بدون دادههای باکیفیت، مدل شما نمیتواند خروجی مناسبی ارائه دهد.
۳. تحلیل و اکتشاف دادهها (Data Exploration & Analysis)
بعد از آمادهسازی دادهها، باید به دنبال الگوها و روابط موجود بین متغیرها بگردید. این مرحله شامل بررسی آماری دادهها و استفاده از ابزارهای بصریسازی مانند نمودارها است. مثلاً ممکن است متوجه شوید که افزایش تبلیغات آنلاین باعث افزایش فروش در مناطق خاصی میشود. این اطلاعات پایهای برای انتخاب ویژگیهای کلیدی و ساخت مدل خواهند بود.
۴. انتخاب و آمادهسازی ویژگیها (Feature Selection & Engineering)
در این مرحله، مشخص میکنید کدام ویژگیها بیشترین تأثیر را بر خروجی دارند و در صورت نیاز، ویژگیهای جدیدی ایجاد میکنید. برای مثال، از ترکیب دو ویژگی موجود میتوانید یک ویژگی جدید بسازید. همچنین دادهها باید استانداردسازی یا نرمالسازی شوند تا مدل بتواند به درستی از آنها استفاده کند. این مرحله نقش مهمی در بهبود دقت و کارایی مدل دارد.
۵. انتخاب الگوریتم و آموزش مدل (Algorithm Selection & Training)
حالا نوبت به انتخاب الگوریتم مناسب میرسد. بسته به نوع مسئله (مثلاً رگرسیون یا دستهبندی) و ویژگیهای دادهها، الگوریتمهای مختلفی مثل رگرسیون خطی، درختهای تصمیمگیری یا شبکههای عصبی میتوانند استفاده شوند. پس از انتخاب، مدل با استفاده از دادههای آموزشی، آموزش داده میشود تا الگوهای موجود در دادهها را یاد بگیرد.
۶. ارزیابی و بهینهسازی مدل (Model Evaluation & Optimization)
بعد از آموزش مدل، عملکرد آن با استفاده از دادههای آزمایشی ارزیابی میشود. معیارهایی مثل دقت، حساسیت و میانگین خطا به شما کمک میکنند بفهمید مدل چقدر خوب عمل میکند. اگر مدل عملکرد قابل قبولی نداشت، میتوانید با تغییر الگوریتم، اصلاح ویژگیها یا تنظیم پارامترها، آن را بهینه کنید.
۷. پیادهسازی و پایش مدل (Model Deployment & Monitoring)
وقتی مدل به دقت کافی رسید، نوبت به استفاده عملی از آن میرسد. مدل میتواند در قالب یک سیستم خودکار یا API پیادهسازی شود. اما کار در اینجا تمام نمیشود! مدل باید به طور مداوم تحت نظر باشد تا در صورت تغییر الگوهای داده یا نیازهای جدید، بهروزرسانی شود.

انواع روشهای ساخت مدل پیشبینی کننده
روشهای مختلفی برای ساخت مدلهای پیشبینی کننده وجود دارد که هر کدام ویژگیها، مزایا و اصول خاص خود را دارند. انتخاب روش مناسب به نوع دادهها، مسئله موردنظر و اهداف شما بستگی دارد. در ادامه، برخی از محبوبترین روشهای ساخت مدل پیشبینی کننده را معرفی کردهایم:
۱. رگرسیون خطی (Linear Regression)
رگرسیون خطی یکی از سادهترین و پرکاربردترین روشهای ساخت مدل پیشبینی کننده است. این روش رابطه بین یک یا چند متغیر مستقل (ویژگیها) و یک متغیر وابسته (خروجی) را به صورت خطی مدلسازی میکند. این مدل برای پیشبینی مقادیر عددی مانند قیمت خانه، فروش ماهانه یا دمای هوا مناسب است. سادگی در پیادهسازی و تفسیر آسان از مزایای این روش میباشد، اما در مواجهه با روابط غیرخطی ممکن است کارایی آن کاهش یابد.
۲. رگرسیون لجستیک (Logistic Regression)
رگرسیون لجستیک برای پیشبینی احتمال وقوع یک رویداد باینری (دو حالته) استفاده میشود. این روش برخلاف نامش، بیشتر برای مسائل طبقهبندی به کار میرود. به عنوان مثال، پیشبینی اینکه یک مشتری خرید میکند یا نه، یا تشخیص بیماری در افراد، نمونههایی از کاربرد این مدل هستند. این روش به دلیل سرعت بالا و دقت مناسب در مسائل ساده باینری بسیار محبوب است.
۳. درخت تصمیم (Decision Tree)
درخت تصمیم از یک ساختار درختی برای مدلسازی تصمیمات و نتایج استفاده میکند. هر گره درخت یک شرط یا سوال است که دادهها را به دستههای کوچکتر تقسیم میکند تا به نتیجه نهایی برسد. این روش برای مسائل طبقهبندی و رگرسیون استفاده میشود و به دلیل سادگی و قابلیت تفسیر، یکی از انتخابهای محبوب برای بسیاری از مسائل پیشبینی است. البته، اگر نظارت کافی نباشد، مدل ممکن است بیشبرازش کند.
۴. ماشین بردار پشتیبان (Support Vector Machine)
ماشین بردار پشتیبان (SVM) دادهها را با استفاده از یک مرز تصمیمگیری (Hyperplane) به کلاسهای مختلف تقسیم میکند. این روش برای مسائل طبقهبندی و رگرسیون به کار میرود و به دلیل دقت بالا و عملکرد مناسب در دادههای پیچیده، مورد توجه قرار گرفته است. با این حال، اجرای آن در دادههای بزرگ میتواند زمانبر و پیچیده باشد.
۵. شبکههای عصبی مصنوعی (Artificial Neural Networks)
شبکههای عصبی مصنوعی از ساختاری شبیه به مغز انسان برای یادگیری روابط پیچیده بین دادهها استفاده میکنند. این روش برای مسائل پیشبینی پیچیده مانند تحلیل تصاویر، شناسایی صدا یا پیشبینی رفتار مشتریان به کار میرود. با اینکه شبکههای عصبی بسیار قدرتمند هستند، اما نیاز به دادههای زیاد، منابع محاسباتی قوی و تخصص بالا دارند. در عوض، میتوانند نتایج فوقالعاده دقیقی ارائه دهند.
سخن آخر
ما در این مقاله سعی کردیم تا به شیوه دقیق، ماهیت مدل پیش بینی کننده و جنبههای مختلف آن را خدمت شما عزیزان شرح دهیم. از طرفی کاربردها و البته الگوریتمهای محبوب در ساخت آنها را مورد ارزیابی قرار دادیم تا شما بهتر بتوانید با این نوآوری بینظیر انسانی آشنا شوید. با این حال اگر هنوز در این رابطه سوال یا ابهامی دارید، میتوانید از طریق بخش نظرات با ما مطرح کنید.
سوالات متداول
مقالات مشابه

برنامه نویسی با هوش مصنوعی
1404/10/14
18 دقیقه

رشته هوش مصنوعی
1404/10/09
18 دقیقه

ایمیل مارکتینگ با هوش مصنوعی
1404/10/07
23 دقیقه

بازار کار هوش مصنوعی
1404/09/30
18 دقیقه

google colab چیست؟
1404/09/27
18 دقیقه
ساخت بازی کامپیوتری با هوش مصنوعی
1404/09/25
14 دقیقه

تولید محتوا با هوش مصنوعی
1404/09/23
25 دقیقه

آشنایی با ابزارهای هوش مصنوعی Google Cloud AI
1404/09/18
24 دقیقه

راهنمای جامع و کاربردی هوش مصنوعی و تحلیل رقبا
1404/09/11
17 دقیقه

آشنایی با ابزارهای هوش مصنوعی Metabase
1404/09/09
17 دقیقه

هوش مصنوعی با MATLAB: از تحلیل داده تا ساخت مدلهای پیشرفته
1404/09/06
25 دقیقه
دانلود اپلیکیشن
ارتقا سطح دانش و مهارت و کیفیت سبک زندگی با استفاده از هوش مصنوعی یک فرصت استثنایی برای انسان هاست.
ثبت دیدگاه
نظری موجود نمیباشد