یادگیری با ناظر(Supervised Learning) چیست؟

جدول محتوایی
- یادگیری با ناظر
- تاریخچه و تکامل یادگیری نظارتشده
- تعریف و مبانی یادگیری با ناظر
- الگوریتمهای پرکاربرد در یادگیری با ناظر
- گام به گام فرایند یادگیری با ناظر
- مزایای کار و آموزش با یادگیری با ناظر
- محدودیت ها و موانع Supervised Learning
- کاربردهای واقعی یادگیری با ناظر در سال های اخیر
- مقایسه یادگیری با ناظر با سایر روشهای یادگیری ماشین
- پیشرفتهای آتی در الگوریتمها و دادههای یادگیری با ناظر
- جمعبندی و نتیجهگیری
در اولین برخورد با پرسش یادگیری با ناظر (Supervised Learning) چیست؟ باید یک کلاس درس را فرض کنید. معلمی که پاسخ را ارائه میدهد و دانشآموزی که تلاش میکند تا از روی پاسخها و مثالهای ارائه شده، یاد میگیرد. معلم داده برچسبدار است و دانشآموز الگوریتم یادگیرنده است.
اهمیت یادگیری با ناظر در این است که بسیاری از کاربردهای روزمره ما بر پایه آن شکل گرفتهاند. از پیشنهاد فیلم و موسیقی در پلتفرمها گرفته تا تشخیص چهره در گوشیهای هوشمند یا پیشبینی رفتار مشتریان در کسبوکار، همه نمونههایی از این نوع یادگیری هستند. دقیقا به خاطر همین حضور در زندگی روزمره، لازم است تا اصول، الگوریتمها، مزایا و محدودیتهای این روش را بشناسید. پس از همین مقاله شروع کنید.
یادگیری با ناظر؛ دروازه به سوی دقت و خطای صفر
یادگیری نظارتشده (Supervised Learning) یکی از ستونهای اصلی یادگیری ماشین است. به کمک این روش مدلها که در واقع مدلهای هوش مصنوعی هستند قادر خواهند بود از دادههای برچسبدار یاد بگیرند و پیشبینیهای دقیقی انجام دهند.
این روش شامل آموزش مدلی با استفاده از جفتهای ورودی-خروجی، مانند متن ایمیل و برچسب اسپم/غیراسپم است تا روابط بین آنها را کشف کند. این رویکرد در قلب بسیاری از فناوریهای مدرن، از تشخیص تقلب بانکی تا پیشبینی قیمت خانه، قرار دارد. به طوری که در سال 2025، یادگیری نظارتشده همچنان بیش از 80% پروژههای هوش مصنوعی را تشکیل میدهد.
اما شاید سوال شما هم این باشد که چرا یادگیری با ناظر روش مهم است؟ یادگیری با ناظر به شرکتها امکان میدهد تصمیمگیریهای سریعتر و دقیقتری داشته باشند. از تحلیل بازار سهام تا بهینهسازی زنجیره تأمین را میتوان با کمک Supervised Learning پیش برد.
از طرفی این روش چالشهایی مانند نیاز به دادههای باکیفیت و خطر سوگیری نیز دارد. تمام این موارد را در ادامه و پس از شناخت مبانی یادگیری با ناظر و روششناسی آن خواهید آموخت. متوجه خواهید شد این روش چه مزایا و معایبی دارد و جایگاه آن در علم امروز کجاست و حتی چه آیندهای در انتظار آن است.

تاریخچه و تکامل یادگیری نظارتشده
یادگیری نظارتشده حاصل تلاشهای اولیه برای تحلیل دادهها با استفاده از روشهای آماری است. این روش از دهه 1950 با الگوریتمهای سادهای مانند رگرسیون خطی که برای پیشبینی مقادیر عددی استفاده میشد، آغاز شد.
در آن زمان، محققانی مانند فرانک روزنبلات با معرفی پرسپترون (Perceptron) در سال 1958، پایهای برای مدلهای یادگیری نظارتشده مدرن گذاشتند. پرسپترون یک مدل اولیه برای طبقهبندی باینری بود که دادههای برچسبدار را برای جداسازی دستهها مانند مثبت یا منفی به کار میبرد. این سیستمها، علیرغم سادگیشان نشان دادند که ماشینها میتوانند با دادههای برچسبدار روابط را یاد بگیرند.
پس از تحقیقات اولیه و در دهههای 1980 و 1990، یادگیری نظارتشده با توسعه الگوریتمهای پیچیدهتر مانند ماشینهای بردار پشتیبان (SVM) و درختهای تصمیم پیشرفت کرد. این الگوریتمها، امکان تحلیل دادههای پیچیدهتر را فراهم کردند.
برای مثال، SVM با ایجاد مرزهای بهینه بین دستهها، دقت طبقهبندی را افزایش داد. حالا اما جهش اصلی در قرن بیستویکم رخ داده است، زمانی که دادههای بزرگ (Big Data) و افزایش قدرت محاسباتی مانند پردازندههای گرافیکی یا GPU یادگیری نظارتشده را متحول کردهاند. در سالهای اخیر دسترسی به حجم عظیمی از دادههای برچسبدار، مانند تصاویر یا متون، به مدلها امکان داده تا الگوهای پیچیدهتری را یاد بگیرند. ظهور یادگیری عمیق (Deep Learning) در دهه گذشته (2010)، با شبکههای عصبی چندلایه، دقت یادگیری با ناظر را به سطح جدیدی رساندهاند. حالا این یادگیری در وظایفی مانند تشخیص تصویر و پردازش زبان طبیعی در هوشهای مصنوعی شگفتی آور شده است.
تعریف و مبانی یادگیری با ناظر
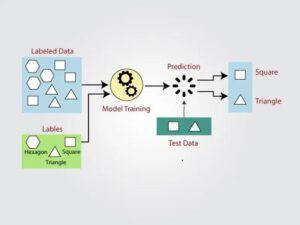
یادگیری با ناظر (Supervised Learning) یک روش یادگیری ماشین است که در آن الگوریتم با استفاده از دادههای ورودی و خروجی مشخص آموزش داده میشود. به بیان ساده، شما مجموعهای از دادهها دارید که هر ورودی آن همراه یک پاسخ درست که به آن Label یا برچسب میگویند هم همراه خود دارد. مدل با مشاهده این دادهها، رابطه بین ورودی و خروجی را یاد میگیرد تا بتواند برای دادههای جدید پیشبینی دقیق انجام دهد.
برای مثال، تصور کنید میخواهیم مدلی بسازیم که ایمیلهای دریافتی را به دو دسته «اسپم» و «غیر اسپم» تقسیم کند. در این حالت، ورودی متن یا ویژگیهای ایمیل است و خروجی برچسبی خواهد بود که نشان میدهد ایمیل اسپم است یا خیر. الگوریتم با دیدن هزاران نمونه از این دادهها، یاد میگیرد چگونه الگوهای مربوط به اسپم را تشخیص دهد.
مفاهیم کلیدی و سازنده در یادگیری با ناظر
در تعریفهای اولیه یادگیری با ناظر دو مفهوم اصلی اهمیت دارند.
- دادههای برچسبدار (Labeled Data): دادههایی که پاسخ درست برای آنها مشخص شده است. بدون این برچسبها یادگیری امکانپذیر نیست. قلب این روش، دادههایی با ورودی (X) و خروجی (Y) مشخص است. برای مثال، در پیشبینی فروش، دادهها شامل ویژگیهای محصول، مثل قیمت و فروش واقعی (برچسب) هستند. کیفیت و تنوع دادهها برای دقت مدل حیاتی است
- تابع نگاشت (Mapping Function): مدلی که الگوریتم در نهایت میسازد، همان رابطهای است که بین ورودیها و خروجیها برقرار میکند.
- الگوریتمهای یادگیری: الگوریتمها مدل را آموزش میدهند تا رابطه بین ورودی و خروجی را یاد بگیرند. الگوریتمهای رایج شامل رگرسیون خطی (برای پیشبینی عددی)، ماشینهای بردار پشتیبان (SVM، برای طبقهبندی)، و شبکههای عصبی (برای وظایف پیچیده مانند تشخیص تصویر) هستند.
- مدل پیشبینی: پس آنکه مدل آموزش دید، قادر خواهد بود جوابی برای دادههای جدید ورودی پیشبینی کند. برای مثال، یک مدل رگرسیون میتواند قیمت یک خانه جدید را بر اساس ویژگیهای آن تخمین بزند.
بنابراین، یادگیری با ناظر را میتوان به نوعی یادگیری از مثالهای آماده دانست؛ مدلی که با مثالهای گذشته آموزش میبیند تا آینده را پیشبینی کند.
انواع وظایف یادگیری نظارتشده
یادگیری نظارتشده به دو نوع اصلی تقسیم میشود:
- طبقهبندی (Classification): پیشبینی یک برچسب گسسته، مانند تشخیص اینکه یک ایمیل اسپم است یا خیر. الگوریتمهایی مثل لجستیک رگرسیون یا درختهای تصمیم طبقهبندی انجام میدهند.
- رگرسیون (Regression): پیشبینی یک مقدار پیوسته، مانند پیشبینی دمای هوا یا قیمت سهام. برای اینکار از رگرسیون خطی و رگرسیون چندجملهای استفاده میشود.
برای مثال، در یک سیستم تشخیص تقلب بانکی، مدل با دادههای تراکنش به عنوان ورودی و برچسبهای «تقلب» یا «عادی» با عنوان خروجی آموزش میبیند تا تراکنشهای مشکوک را شناسایی کند. این مثال نشان میدهد که یادگیری نظارتشده چگونه با دادههای برچسبدار به پیشبینیهای دقیق میرسد.
الگوریتمهای پرکاربرد در یادگیری با ناظر
یادگیری با ناظر بر پایه مجموعهای از الگوریتمها بنا شده که هر کدام برای نوع خاصی از مسئله طراحی شدهاند. در ادامه، مهمترین آنها را توضیح میدهیم و مثال میزنیم تا کاملا با مفهوم یادگیری با ناظر چیست، آشنا شوید.
رگرسیون خطی (Linear Regression)
این الگوریتم برای پیشبینی مقادیر عددی استفاده میشود. فرض کنید یک مشاور املاک میخواهد قیمت خانه را بر اساس متراژ و موقعیت آن تخمین بزند. رگرسیون خطی با پیدا کردن یک خط یا معادلهی ساده، رابطه میان این ویژگیها و قیمت خانه را مدلسازی میکند.
رگرسیون لجستیک (Logistic Regression)
در حالی که نامش «رگرسیون» است، در عمل بیشتر برای طبقهبندی کاربرد دارد. مثلا سیستم ضد اسپم جیمیل با کمک رگرسیون لجستیک یاد میگیرد که یک ایمیل با توجه به کلمات موجود در متن و آدرس فرستنده، «اسپم» است یا «غیر اسپم».
درخت تصمیم (Decision Tree)
درخت تصمیم با پرسشهای متوالی دادهها را طبقهبندی میکند. مثلا یک پزشک میتواند از درخت تصمیم برای تشخیص بیماری استفاده کند: «آیا بیمار تب دارد؟»، «آیا سرفهی خشک دارد؟» و در نهایت به نتیجهای مانند «احتمال ابتلا به آنفولانزا» برسد. مزیت این الگوریتم، سادگی و قابلفهم بودنش است.

جنگل تصادفی (Random Forest)
مدل قبلی ممکن است خطا داشته باشد، در این حالت از مدل جنگل تصادفی استفاده خواهد شد، مخصوصا اگر دادههای ورودی زیاد باشند. جنگل تصادفی با ترکیب چندین درخت، دقت را بالا میبرد. برای مثال، در یک سیستم اعتبارسنجی بانکی، الگوریتم بر اساس صدها تصمیمگیری کوچک مثل سن مشتری، درآمد یا سوابق پرداخت پیشبینی میکند که آیا فرد وام را بهموقع بازپرداخت خواهد کرد یا خیر.
ماشین بردار پشتیبان (Support Vector Machine)
SVM تلاش میکند بهترین مرز را برای جداسازی دادهها پیدا کند. مثلا در یک پروژه پزشکی، دادههای بیماران «سالم» و «بیمار» با ویژگیهایی مثل فشار خون و سطح کلسترول روی نمودار رسم میشوند. SVM خط یا مرزی را رسم میکند که این دو گروه را با بیشترین فاصله ممکن از هم جدا کند.
نزدیک ترین همسایه (k-Nearest Neighbors)
این الگوریتم بر اساس شباهت کار میکند. اگر قرار باشد فیلمهای جدید داخل هاردتان را در دسته «اکشن» یا «کمدی» قرار دهید، این الگوریتم کارتان را راحت خواهد کرد. kNN بررسی میکند که فیلم جدید بیشتر شبیه کدام دسته از فیلمهای موجود است، مثلا بر اساس میزان خشونت یا شوخی و برچسب را بر همان اساس تعیین میکند.
شبکههای عصبی مصنوعی (Artificial Neural Networks)
شبکه عصبی مصنوعی که در دهههای اخیر پرکاربردترین مدل یادگیری با ناظر است، از مغز انسان الهام میگیرد و در مسائل پیچیده بسیار موفق عمل میکند. برای نمونه، اپلیکیشنهای تشخیص چهره مثل Face ID در آیفون از شبکههای عصبی استفاده میکنند تا با بررسی الگوهای صورت کاربر، او را شناسایی کنند.

گام به گام فرایند یادگیری با ناظر
یادگیری با ناظر یک چرخه مشخص دارد که تقریبا در تمام پروژههای هوش مصنوعی دنبال میشود. این فرایند را میتوان در چند گام اصلی خلاصه کرد که در ادامه این بخش با جزئیات برایتان شرح میدهیم.
جمعآوری دادههای برچسبدار
اولین و مهمترین مرحله در آموزش به شیوه یادگیری با ناظر، تهیه دادههای مناسب است. کیفیت و کمیت دادهها نقش مستقیم در دقت مدل دارد. به عنوان نمونه، در یک پروژه تشخیص بیماری قلبی، باید مجموعهای از اطلاعات بیماران شامل فشار خون، سن و نتایج آزمایشها همراه با برچسب «بیمار/سالم» در اختیار مدل قرار گیرد.
تقسیم دادهها به آموزش و تست
ناظر برای آن که مطمئن شود مدل فقظ دادهها را حفظ نکرده است و برای جلوگیری از خطا، دادهها را به دو بخش تقسیم میکند.
- Training set: بخش بزرگتر دادهها که باید برای آموزش مدل استفاده شود.
- Test set: بخش کوچکتر که برای ارزیابی عملکرد مدل روی دادههای جدید کنار گذاشته میشود.
این دو بخش به مدل داده میشود و ناظر با آزمون و خطا، خطاهای آینده را حذف میکند.
آموزش مدل
در این مرحله الگوریتم انتخابشده، مثلا درخت تصمیم یا رگرسیون روی دادههای آموزشی اجرا میشود. هدف ناظر در این مرحله این است که مدل بهترین الگوها و روابط را بیابد.
اعتبارسنجی و ارزیابی
پس از آموزش، مدل روی دادههای تست آزمایش میشود تا ببینیم تا چه حد میتواند نتایج درست را پیشبینی کند. در این مرحله از معیارهایی مانند دقت (Accuracy)، Precision یا Recall برای ارزیابی استفاده میشوند.
بهبود و بازآموزی
در نهایت، اگر عملکرد مدل رضایتبخش نباشد، تمام این مراحل از اول تکرار میشوند: دادهها اصلاح میشوند، الگوریتم تغییر میکند یا پارامترها تنظیم میشوند. درست مانند یک چرخه که اصل یادگیری با ناظر نیز روی این چرخه آموزش و نتیجه بنا شده است.
مزایای کار و آموزش با یادگیری با ناظر
یادگیری با ناظر به دلیل استفاده از دادههای برچسبدار، مزایای قابلتوجهی در پیشبینی و تصمیمگیری ارائه میدهد.
- دقت بالا در وظایف مشخص: مدلهای نظارتشده در وظایفی مانند طبقهبندی و رگرسیون، بهویژه با دادههای باکیفیت، دقت بالایی دارند. برای مثال، سیستمهای تشخیص پزشکی میتوانند سرطان را در تصاویر MRI با دقتی بیش از 95% شناسایی کنند.
- کاربرد گسترده: این روش در حوزههای متنوع، از تشخیص اسپم ایمیل تا پیشبینی تقاضای بازار، استفاده میشود. یادگیری با ناظر در بیش از 80% پروژههای هوش مصنوعی در سال 2025 نقش کلیدی دارد، بهویژه در تحلیل دادههای تجاری.
- پیادهسازی سریع با ابزارهای موجود: کتابخانههایی مانند Scikit-learn و TensorFlow امکان توسعه سریع مدلها را فراهم میکنند. این ابزارها به توسعهدهندگان اجازه میدهند تا با حداقل پیچیدگی، مدلهای دقیق بسازند.
- بهبود تصمیمگیری: یادگیری با ناظر با ارائه پیشبینیهای قابلاعتماد، تصمیمگیری در صنایعی مانند مالی و لجستیک را بهبود میبخشد، مثلاً با پیشبینی بهینه مسیرهای حملونقل.
باتوجهبه این موارد متوجه میشوید که یادگیری با ناظر تصمیمگیریهای مبتنی بر داده را در صنایع مختلف تقویت میکند و پیادهسازی سریع و کارآمدی ارائه میدهد.
محدودیت ها و موانع Supervised Learning
علیرغم مزایای کاربردی که یادگیری با ناظر دارد، از طرفی با محدودیتها و چالشهایی روبهرو است که عملکرد آن را محدود میکند.
- نیاز به دادههای برچسبدار: برچسبگذاری دادهها زمانبر و پرهزینه است. برای مثال، برچسبگذاری تصاویر پزشکی برای تشخیص بیماری نیاز به متخصصان همان حوزه دارد.
- بیشبرازش (Overfitting): مدل ممکن است بیش از حد به دادههای آموزشی وابسته شود و در دادههای جدید عملکرد ضعیفی داشته باشد. تکنیکهایی مانند regularization و cross-validation این مشکل را کاهش میدهند.
- سوگیری در دادهها: اگر دادههای آموزشی جهتدار باشند، مدل نتایج ناعادلانهای تولید میکند، مانند سیستمهای تشخیص چهره که در گروههای نژادی خاص دقت کمتری دارند.
- هزینههای محاسباتی: مدلهای پیچیده مانند شبکههای عصبی عمیق نیاز به منابع محاسباتی گرانقیمت دارند. با این حال در سال 2025، رویکردهایی مانند active learning و weak supervision برای کاهش وابستگی به دادههای برچسبدار در حال گسترش هستند.
این فرآیندها و ابزارها یادگیری با ناظر را به روشی قدرتمند برای پیشبینی تبدیل کردهاند، اما نیاز به مدیریت دقیق چالشها دارند.

کاربردهای واقعی یادگیری با ناظر در سال های اخیر
یادگیری با ناظر در حوزههای مختلف، از زندگی روزمره تا صنایع پیشرفته، برای پیشبینی و تصمیمگیری دقیق به کار میرود. در سال 2025، یادگیری با ناظر در بیش از 80% پروژههای هوش مصنوعی برای کاربردهایی مانند تحلیل پزشکی، بهینهسازی لجستیک و پردازش زبان طبیعی استفاده میشود. در زیر کاربردهای مهم این روش که قطعا با آنها سر و کار دارید را میخوانید.
- تشخیص اسپم ایمیل: مدلهای طبقهبندی با دادههای برچسبدار (اسپم/غیراسپم) ایمیلهای ناخواسته را با دقت بالا فیلتر میکنند.
- سیستمهای توصیهگر: در نتفلیکس و آمازون، مدلها رفتار کاربر را تحلیل میکنند و فیلم یا محصول مناسب پیشنهاد میدهند.
- تشخیص پزشکی: مدلهای رگرسیون و طبقهبندی تصاویر پزشکی (مانند MRI) را تحلیل کرده و به تشخیص بیماریهایی مانند سرطان را کمک میکنند.
- تشخیص تقلب مالی: تحلیل دادههای برچسب دارد و شناسایی تراکنشهای مشکوک برای جلوگیری از تقلب در بانکها.
- پیشبینی بازار: مدل رگرسیون برای پیشبینی قیمت سهام یا تقاضای بازار با دادههای تاریخی استفاده میشود.
- نگهداری پیشبینانه: به کمک پیشبینی مدل برای خرابی ماشینآلات در صنایع که از هزینههای جانبی و ناخواسته جلوگیری میکند.
- تحلیل تصاویر ماهوارهای: به طور مثال در کشاورزی، مدلها دادههای برچسبدار را برای بهینهسازی کاشت تحلیل میکنند.
- پردازش زبان طبیعی: مدلهایی مانند BERT با تحلیل متون، در جستجو یا چتباتها استفاده میشوند.
یادگیری با ناظر با پیشبینیهای دقیق، زندگی و صنایع را متحول میکند، اما همچنان چالشهایی مانند سوگیری دادهها نیاز به بررسی دارند.
مقایسه یادگیری با ناظر با سایر روشهای یادگیری ماشین
برای درک بهتر جایگاه یادگیری با ناظر، لازم است آن را با دو روش مهم دیگر مقایسه کنیم. یادگیری بدون ناظر (Unsupervised Learning) و یادگیری تقویتی (Reinforcement Learning).
یادگیری بدون ناظر (Unsupervised Learning)
در یادگیری بدون ناظر دادهها برچسب ندارند و مدل باید ساختارها یا الگوهای پنهان را کشف کند. این روش در خوشهبندی مشتریان بر اساس رفتار خرید بدون اطلاع قبلی از دستهبندی آنها کاربرد دارد. تفاوت این روش با یادگیری با ناظر در هدفی است که دنبال میکنند. در یادگیری با ناظر، مدل پیشبینی دقیقی برای خروجی مشخص انجام میدهد، اما در یادگیری بدون ناظر، هدف کشف الگوهاست.
یادگیری تقویتی (Reinforcement Learning)
یادگیری تقویتی بر اساس سیستم پاداش و جریمه کار میکند. در واقع در این حالت مدل با دریافت پاداش یا جریمه از محیط یاد میگیرد. این روش بیشتر در بازیهای ویدیویی یا رباتهای خودران کاربرد دارد.
تفاوت این روش با یادگیری با ناظر، آن است که در Supervised Learning هر ورودی خروجی مشخص دارد. در مقابل برای یادگیری تقویتی، مدل باید با امتحان و خطا بیاموزد و هیچ پاسخ صحیح اولیهای ارائه نمیشود.

پیشرفتهای آتی در الگوریتمها و دادههای یادگیری با ناظر
یادگیری با ناظر در سالهای آینده با بهبود الگوریتمها و روشهای مدیریت دادهها پیشرفتهای چشمگیری خواهد داشت. با بررسیهای استفاده از این روش در مدلهای مختلف مشخص میشود که روشهایی مانند active learning و weak supervision در سال 2025 محبوبیت بیشتری پیدا کردهاند. این ترکیب قرار است وابستگی به دادههای برچسبدار پرهزینه را کاهش دهند.
به این ترتیب یادگیری با ناظر با انتخاب هوشمند دادهها برای برچسبگذاری یا استفاده از برچسبهای خودکار، هزینهها را کم خواهد کرد.
از طرفی یادگیری نظارتشده با فناوریهای جدید مانند اینترنت اشیا (IoT) و edge computing ادغام میشود تا کاربردهای جدیدی ایجاد کند. برای مثال، در شهرهای هوشمند، مدلهای نظارتشده با تحلیل دادههای حسگرهای IoT، مصرف انرژی یا ترافیک را بهینه میکنند.
همچنین، ترکیب یادگیری با ناظر با self-supervised learning که در آن مدلها از دادههای بدون برچسب برای پیشآموزش استفاده میکنند، در حال گسترش است. این رویکرد، که در مدلهایی مانند BERT دیده میشود، نیاز به برچسبگذاری دستی را کاهش داده و کارایی را بهبود میبخشد.
در نهایت پیشبینی میشود که در دهه آینده، یادگیری با ناظر در حوزههایی مانند آموزش شخصیسازیشده، مراقبتهای بهداشتی و کشاورزی دقیق نفوذ بیشتری خواهد داشت. برای مثال، مدلهای با ناظر میتوانند برنامههای درسی را بر اساس نیازهای دانشآموزان تنظیم کنند یا در کشاورزی، با تحلیل دادههای ماهوارهای، بهرهوری را افزایش دهند.
جمعبندی و نتیجهگیری
حال و با خواندن تمام این جزئیات میدانید که یادگیری نظارتشده بهعنوان یکی از ارکان اصلی یادگیری ماشین، نقشی محوری در پیشبینیهای دقیق و تصمیمگیریهای هوشمند ایفا میکند. از تعاریف گرفته تا مزایا و معایب و تفاوتهای آن با سایر مدلها را میدانید و کاربردهای آن را میشناسید.
با توجه به پیشرفتهای این مدل تصور میشود تا سال 2030، یادگیری نظارتشده با ادغام فناوریهایی مانند اینترنت اشیا و مدلهای ترکیبی، در حوزههایی مانند آموزش شخصیسازیشده و کشاورزی دقیق نفوذ بیشتری داشته باشد.
در نهایت میتوان گفت یادگیری با ناظر نهتنها فناوریهای امروزی را قدرت میبخشد، بلکه پایهای برای پیشرفتهای آینده هوش مصنوعی است. این روش دریچهای به دنیای دادههای هوشمند است.
چکیده
یادگیری با ناظر (Supervised Learning) یکی از اصلیترین روشهای یادگیری ماشین (Machine Learning) است که با استفاده از دادههای برچسبدار (Labeled Data)، الگوریتمها را قادر میسازد روابط میان ورودیها و خروجیها را بیاموزند و پیشبینی دقیق (Accurate Prediction) انجام دهند. این روش در کاربردهای متنوعی مانند تشخیص اسپم (Spam Detection)، پیشبینی قیمتها (Price Prediction)، تشخیص چهره (Face Recognition)، پردازش زبان طبیعی (Natural Language Processing) و تشخیص بیماری در پزشکی (Medical Diagnosis) استفاده میشود.
مزایای اصلی آن شامل دقت بالا (High Accuracy)، سرعت آموزش سریع (Fast Training) و قابلیت تفسیر مدلها (Model Interpretability) است. از طرفی نیاز به دادههای برچسبدار زیاد و حساسیت به کیفیت دادهها از چالشهای آن محسوب میشوند. با پیشرفتهای نوین مانند یادگیری نیمهنظارتی (Semi-Supervised Learning) و ابزارهای AutoML، Supervised Learning همچنان ستون اصلی بسیاری از سیستمهای هوش مصنوعی مدرن (Modern AI Systems) است و نقش حیاتی در تصمیمگیری هوشمند (Intelligent Decision-Making) و شخصیسازی خدمات (Personalized Services) دارد.
سوالات متداول
مقالات مشابه

برنامه نویسی با هوش مصنوعی
1404/10/14
18 دقیقه

رشته هوش مصنوعی
1404/10/09
18 دقیقه

ایمیل مارکتینگ با هوش مصنوعی
1404/10/07
23 دقیقه

بازار کار هوش مصنوعی
1404/09/30
18 دقیقه

google colab چیست؟
1404/09/27
18 دقیقه
ساخت بازی کامپیوتری با هوش مصنوعی
1404/09/25
14 دقیقه

تولید محتوا با هوش مصنوعی
1404/09/23
25 دقیقه

آشنایی با ابزارهای هوش مصنوعی Google Cloud AI
1404/09/18
24 دقیقه

راهنمای جامع و کاربردی هوش مصنوعی و تحلیل رقبا
1404/09/11
17 دقیقه

آشنایی با ابزارهای هوش مصنوعی Metabase
1404/09/09
17 دقیقه

هوش مصنوعی با MATLAB: از تحلیل داده تا ساخت مدلهای پیشرفته
1404/09/06
25 دقیقه
دانلود اپلیکیشن
ارتقا سطح دانش و مهارت و کیفیت سبک زندگی با استفاده از هوش مصنوعی یک فرصت استثنایی برای انسان هاست.
ثبت دیدگاه
نظری موجود نمیباشد