مدل ترنسفورمر (Transformer Model) چیست؟
جدول محتوایی
- مقدمه
- مدل ترنسفورمر چیست و چرا اهمیت دارد؟
- تاریخچه پیدایش مدلهای ترنسفورمر در هوش مصنوعی
- تفاوت Self-Attention با Attention معمولی
- لایه Decoder در ترنسفورمر چیست و چه کاربردی دارد؟
- آموزش مدل ترنسفورمر (Training) و بهینهسازی آن
- ترنسفورمر و پردازش زبان طبیعی (NLP)
- ترنسفورمر و کاربرد آن در ترجمه ماشینی
- نقش ترنسفورمر در تولید متن و چتباتها
- معماری GPT و تفاوت آن با BERT
- از GPT-1 تا GPT-5: تحول مدلهای زبانی بر پایه ترنسفورمر
- ترنسفورمر در حوزه گفتار و تشخیص صدا
- کاربردهای ترنسفورمر در جستجوگرها و موتورهای هوشمند
- ترنسفورمر در صنعت: پزشکی، آموزش و تجارت
- مزایا و محدودیتهای مدل ترنسفورمر
- تکنیکهای بهینهسازی و فشردهسازی مدلهای ترنسفورمر
- چرا ترنسفورمرها در ایران هم محبوب شدهاند؟
- بهترین منابع آموزشی برای یادگیری مدل ترنسفورمر
- جمعبندی
مقدمه
مدل ترنسفورمر (Transformer Model) چیست؟ این پرسشی است که امروزه ذهن بسیاری از علاقهمندان و فعالان حوزه هوش مصنوعی (AI) را به خود مشغول کرده است. از زمانی که مقاله معروف «Attention is All You Need» در سال ۲۰۱۷ معرفی شد، معماری ترنسفورمر به نقطه عطفی در تاریخ یادگیری ماشین و پردازش زبان طبیعی تبدیل شد. این مدل نه تنها محدودیتهای شبکههای عصبی سنتی مانند RNN و LSTM را برطرف کرد، بلکه راه را برای ساخت ابزارهایی همچون BERT، GPT و حتی سایتهای هوش مصنوعی آنلاین هموار ساخت.
در این مقاله جامع، از پایه تا پیشرفته، معماری ترنسفورمر، کاربردها، مزایا، چالشها و آینده آن را بررسی میکنیم تا پاسخی روشن به پرسش شما بدهیم که «چرا ترنسفورمر به قلب دنیای هوش مصنوعی تبدیل شده است؟».
مدل ترنسفورمر چیست و چرا اهمیت دارد؟
مدل ترنسفورمر (Transformer Model) یکی از مهمترین دستاوردهای هوش مصنوعی (AI) در سالهای اخیر است که توانست تحولی عظیم در پردازش زبان طبیعی ایجاد کند. این مدل در واقع معماریای برای درک و تولید دادههای ترتیبی مثل متن است. ترنسفورمر برخلاف مدلهای قدیمیتر مانند RNN یا LSTM میتواند بهطور همزمان کل یک جمله یا متن را پردازش کند و به جای یادگیری وابستگیهای کوتاه، وابستگیهای طولانیمدت بین کلمات را نیز در نظر بگیرد.
اهمیت ترنسفورمر زمانی مشخص میشود که بدانیم فناوریهایی مانند چتباتها، مترجم گوگل، و دستیارهای هوش مصنوعی آنلاین همه بر پایه همین مدل ساخته شدهاند. به عنوان مثال، وقتی در یک سایت هوش مصنوعی یک پرسش مینویسید، ترنسفورمر میتواند ارتباط بین واژهها را درک کند و پاسخی دقیق ارائه دهد.
به طور خلاصه، ترنسفورمر قلب بسیاری از ابزارهای مدرن هوش مصنوعی است. بدون این معماری، سیستمهای زبانی قدرتمندی مثل GPT یا BERT وجود نداشتند. همین مسئله نشان میدهد چرا وقتی صحبت از «استفاده از هوش مصنوعی» میشود، نقش مدل ترنسفورمر غیرقابل انکار است.
تاریخچه پیدایش مدلهای ترنسفورمر در هوش مصنوعی
تا قبل از سال ۲۰۱۷، بیشتر مدلهای پردازش زبان بر پایه RNN یا LSTM بودند. این مدلها قادر به درک توالی دادهها بودند، اما مشکل اصلی آنها سرعت پایین و ناتوانی در پردازش وابستگیهای طولانیمدت بود. در سال ۲۰۱۷، مقاله معروف گوگل با عنوان “Attention is All You Need” منتشر شد که در آن مدل ترنسفورمر معرفی شد.
این معماری به جای استفاده از ساختارهای بازگشتی، از مکانیزم توجه (Attention) بهره گرفت. همین نوآوری باعث شد ترنسفورمر به سرعت در میان پژوهشگران هوش مصنوعی محبوب شود. بهعنوان مثال، مدلهای قدرتمندی مثل BERT (2018) برای درک زبان و GPT (2018 تا امروز) برای تولید متن بر اساس ترنسفورمر ساخته شدند.
از همان زمان، بسیاری از سایتهای هوش مصنوعی و ابزارهای هوش مصنوعی آنلاین شروع به استفاده از این مدل کردند. امروز اگر به دنبال ترجمه ماشینی، تولید متن یا حتی خلاصهسازی مقالات باشید، ترنسفورمر در پشت صحنه کار میکند. این تاریخچه نشان میدهد که چگونه تنها در چند سال، این مدل از یک مقاله علمی به قلب صنعت AI و ابزارهای پرکاربرد روزمره تبدیل شد.
مشکل شبکههای عصبی سنتی (RNN و LSTM) و نیاز به ترنسفورمر
شبکههای RNN و LSTM زمانی پیشرفتهترین ابزارهای هوش مصنوعی برای پردازش زبان طبیعی بودند. این مدلها دادهها را به صورت ترتیبی (یکی بعد از دیگری) پردازش میکردند. مشکل اصلی این بود که وقتی یک متن طولانی وارد میشد، مدل توانایی یادآوری اطلاعات ابتدای جمله را از دست میداد. به این مشکل Gradient Vanishing گفته میشود.
مثلاً اگر جملهای طولانی مثل:
«دانشجویان با تلاش فراوان در امتحان موفق شدند چون …»
را به مدل بدهیم، RNN یا LSTM ممکن است بخش «چون» و علت موفقیت را بهخوبی با ابتدای جمله ارتباط ندهد.
علاوه بر این، آموزش RNN بسیار زمانبر بود و به سختافزار قوی نیاز داشت. به همین دلیل، پژوهشگران به دنبال روشی سریعتر و دقیقتر بودند. اینجا بود که ترنسفورمر معرفی شد. ترنسفورمر با مکانیزم توجه، کل جمله را یکجا پردازش میکند و میتواند روابط کلمات دور از هم را نیز پیدا کند.
به همین دلیل، امروزه در اغلب سایتهای هوش مصنوعی و ابزارهای هوش مصنوعی آنلاین دیگر خبری از RNN نیست و جای آن را ترنسفورمر گرفته است.
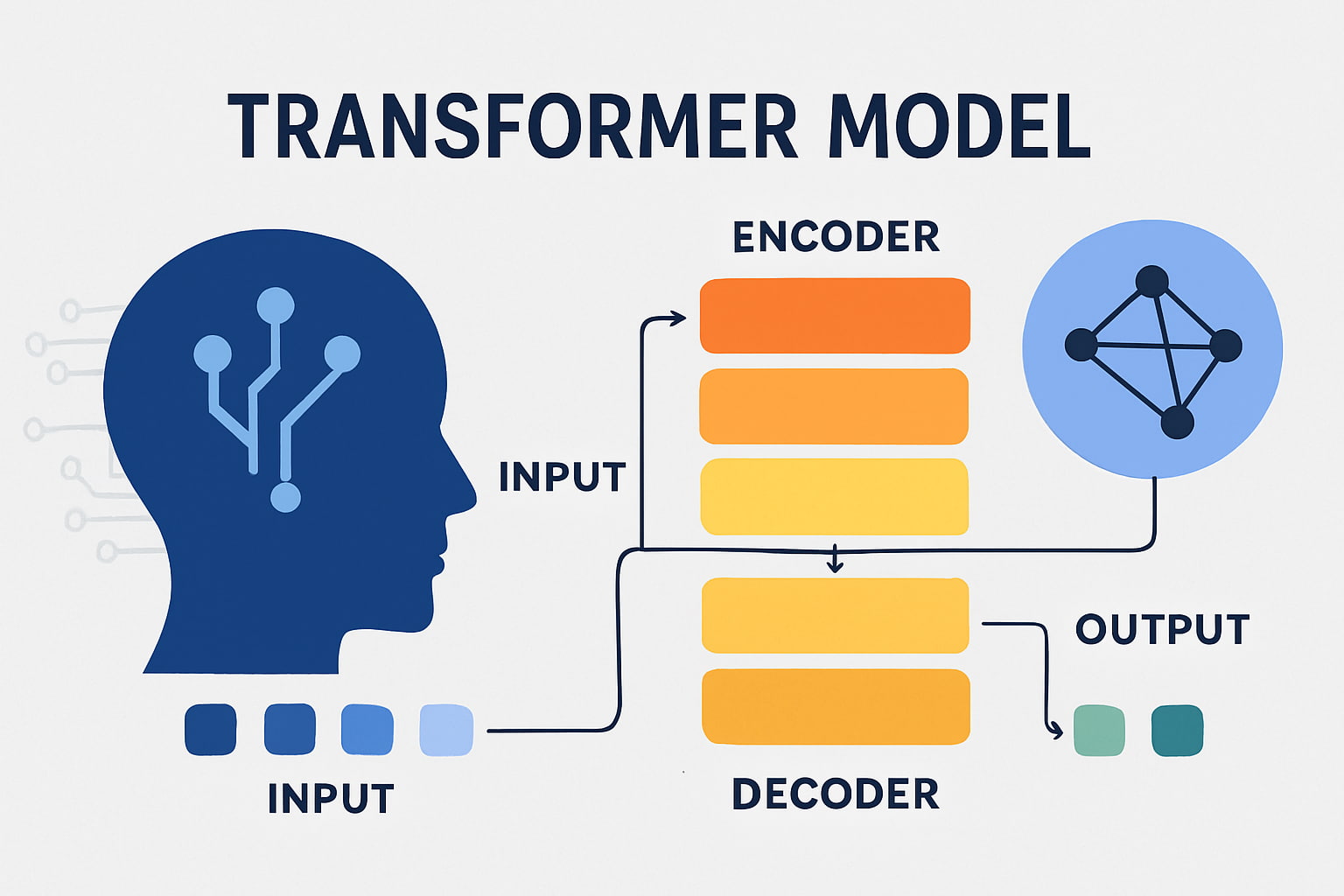
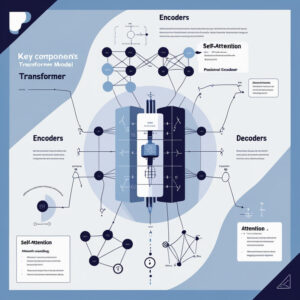
معماری مدل ترنسفورمر به زبان ساده
معماری ترنسفورمر در نگاه اول پیچیده به نظر میرسد، اما میتوان آن را به زبان ساده توضیح داد. این مدل از دو بخش اصلی تشکیل شده است: Encoder و Decoder. Encoder وظیفه دارد متن ورودی را بخواند و آن را به یک نمایش برداری (Vector Representation) تبدیل کند. Decoder سپس از این نمایش برای تولید خروجی استفاده میکند.
کلید موفقیت ترنسفورمر در استفاده از Self-Attention است. به کمک این مکانیزم، مدل میتواند ارتباط بین هر کلمه با تمام کلمات دیگر جمله را پیدا کند. برای مثال در جمله «کتاب را روی میز گذاشتم»، کلمه «کتاب» باید با «گذاشتم» مرتبط شود، نه فقط با کلمه کناریاش.
در معماری ترنسفورمر چندین لایه Encoder و Decoder روی هم قرار گرفتهاند که هرکدام اطلاعات بیشتری را پردازش میکنند. این ساختار باعث شده ترنسفورمر بسیار قدرتمند باشد و در کارهایی مثل ترجمه ماشینی یا تولید متن عملکردی شگفتانگیز ارائه دهد.
امروز بسیاری از ابزارهای هوش مصنوعی آنلاین و حتی سایتهای هوش مصنوعی دقیقاً از همین معماری استفاده میکنند.
مکانیزم توجه (Attention Mechanism) چیست؟
یکی از مفاهیم کلیدی در ترنسفورمر مکانیزم توجه یا Attention Mechanism است. توجه در واقع روشی است که به مدل اجازه میدهد اهمیت نسبی هر کلمه در جمله را درک کند. به زبان ساده، مدل یاد میگیرد روی بخشهای مهمتر تمرکز کند.
مثلاً در جمله:
«علی کتابی را که دیروز خریده بود به دوستش داد.»
اگر بخواهیم بدانیم «را» به کدام اسم اشاره دارد، مدل باید توجه بیشتری به «کتاب» داشته باشد. مکانیزم توجه دقیقاً این کار را انجام میدهد.
فرمول اصلی توجه وزنهای متفاوتی به هر کلمه اختصاص میدهد تا مشخص شود کدام کلمه برای درک معنای جمله مهمتر است. به همین دلیل، ترنسفورمر قادر است جملات طولانی را هم بهخوبی تحلیل کند.
این مکانیزم یکی از دلایل اصلی محبوبیت ترنسفورمر در هوش مصنوعی AI است. بدون آن، ابزارهای قدرتمند امروزی مثل چتباتهای هوش مصنوعی آنلاین یا سیستمهای ترجمه در سایتهای هوش مصنوعی امکانپذیر نبودند.
تفاوت Self-Attention با Attention معمولی
مکانیزم Attention به مدل کمک میکند که هنگام پردازش یک کلمه، به بقیه کلمات جمله هم توجه کند. اما تفاوت اصلی بین Attention معمولی و Self-Attention در این است که در Attention معمولی، توجه بین دو دنباله جداگانه (مثلاً جمله ورودی و خروجی) محاسبه میشود. در حالی که در Self-Attention، هر کلمه در یک دنباله با تمام کلمات همان دنباله مقایسه میشود.
برای مثال، در جمله:
«دانشآموزان در مدرسه فوتبال بازی کردند.»
کلمه «بازی» در Self-Attention بررسی میکند که بیشتر با «دانشآموزان» ارتباط دارد یا با «مدرسه». این باعث میشود مدل درک عمیقتری از جمله داشته باشد.
به همین دلیل، Self-Attention ستون فقرات معماری ترنسفورمر است. این ویژگی باعث شده مدلهای زبانی مانند GPT یا BERT بتوانند متون طولانی را با دقت فوقالعاده پردازش کنند. امروز وقتی در یک سایت هوش مصنوعی آنلاین متنی وارد میکنید، در پشت صحنه Self-Attention است که معنای درست جملات را استخراج میکند.
مفهوم Multi-Head Attention در ترنسفورمر
یکی از مهمترین نوآوریهای مدل ترنسفورمر استفاده از Multi-Head Attention است. در این مکانیزم، مدل توجه را نه فقط یک بار، بلکه چندین بار به صورت موازی انجام میدهد. هر «Head» یا سر توجه به روابط متفاوتی میان کلمات نگاه میکند.
به عنوان مثال، در جمله:
«کتاب جدید نویسنده مشهور برنده جایزه شد.»
یک Head ممکن است روی ارتباط «کتاب» و «جایزه» تمرکز کند، در حالی که Head دیگر روی ارتباط «نویسنده» و «مشهور» تمرکز کند. در نهایت همه این نتایج با هم ترکیب میشوند تا درک جامعتری از جمله به دست آید.
این رویکرد باعث شده مدل ترنسفورمر توانایی خارقالعادهای در تحلیل زبان پیدا کند. همین Multi-Head Attention است که قدرت سیستمهای هوش مصنوعی AI مثل چتباتها و مترجمهای آنلاین را ممکن میسازد. در واقع، وقتی شما در یک سایت هوش مصنوعی یک متن طولانی وارد میکنید، Multi-Head Attention تضمین میکند که حتی جزئیترین روابط هم از دست نروند.
جایگاه Embedding در مدل ترنسفورمر
برای اینکه مدل ترنسفورمر بتواند متن را پردازش کند، ابتدا باید کلمات به شکل عددی تبدیل شوند. این مرحله با استفاده از Embedding انجام میشود. در Embedding هر کلمه به یک بردار (Vector) با ابعاد ثابت تبدیل میشود که نماینده معنای آن کلمه است.
به عنوان مثال، کلمات «کتاب» و «دفتر» در فضای برداری به نقاطی نزدیک به هم نگاشته میشوند چون معنای مشابهی دارند. در مقابل، کلمه «ماشین» فاصله بیشتری خواهد داشت. این نمایش عددی باعث میشود مدل بتواند شباهتها و تفاوتهای معنایی را درک کند.
Embeddingها در هوش مصنوعی آنلاین کاربرد گسترده دارند. بهطور مثال در موتورهای جستجو یا سایتهای هوش مصنوعی وقتی عبارتی را وارد میکنید، سیستم از Embedding برای یافتن نتایج مشابه استفاده میکند.
در ترنسفورمر، Embedding اولین مرحله است که داده متنی خام را به فرم قابل فهم برای مدل تبدیل میکند. بدون آن، مکانیزمهایی مثل Self-Attention عملاً امکانپذیر نبودند.
نقش Positional Encoding در فهم ترتیب کلمات
یکی از مشکلات ترنسفورمر این است که برخلاف RNN، ترتیب کلمات را به صورت ذاتی نمیفهمد. برای رفع این مشکل، از Positional Encoding استفاده میشود. این تکنیک به هر کلمه علاوه بر بردار Embedding، یک بردار اضافی اضافه میکند که نشاندهنده موقعیت آن در جمله است.
برای مثال، در جمله:
«من به پارک رفتم.»
کلمه «من» در جایگاه اول است و «رفتم» در انتهای جمله. اگر ترتیب رعایت نشود، مدل ممکن است تصور کند «پارک من به رفتم» هم درست است. اما با Positional Encoding، مدل میفهمد که ترتیب نقش اساسی در معنا دارد.
در عمل، این ویژگی باعث میشود ترنسفورمر بتواند ترجمههای دقیقتری ارائه دهد یا متونی بسازد که کاملاً طبیعی به نظر برسند. امروزه بسیاری از سایتهای هوش مصنوعی که خدمات ترجمه یا تولید متن ارائه میدهند، دقیقاً از همین قابلیت استفاده میکنند تا جملات بینقصی تولید شود.
لایه Encoder در ترنسفورمر چگونه کار میکند؟
Encoder بخش اول معماری ترنسفورمر است و وظیفه اصلی آن فهم دقیق متن ورودی است. هر Encoder شامل چندین لایه است که هر کدام شامل دو بخش کلیدی هستند: Self-Attention و یک شبکه عصبی Feed Forward.
فرآیند به این صورت است: ابتدا کلمات ورودی به Embedding و سپس Positional Encoding تبدیل میشوند. سپس مکانیزم Self-Attention روابط بین کلمات را مشخص میکند. در نهایت، لایه Feed Forward این اطلاعات را پردازش کرده و خروجی را به لایه بعدی میفرستد.
به عنوان مثال، اگر جمله «دانشجو در کتابخانه مطالعه کرد» را وارد کنیم، Encoder روابط بین «دانشجو» و «مطالعه» یا «کتابخانه» را استخراج میکند. این نمایش فشرده از معنا، پایهای برای تولید متن یا ترجمه خواهد بود.
امروز ابزارهای هوش مصنوعی آنلاین و سایتهای هوش مصنوعی از Encoder استفاده میکنند تا معنای ورودی کاربر را بفهمند و سپس پاسخی متناسب تولید کنند. به همین دلیل، Encoder به نوعی «مغز درک کننده» ترنسفورمر محسوب میشود.
لایه Decoder در ترنسفورمر چیست و چه کاربردی دارد؟
Decoder بخش دوم معماری ترنسفورمر است و وظیفه اصلی آن تولید خروجی بر اساس دادههای ورودی پردازششده توسط Encoder است. در واقع Encoder جمله را میفهمد و Decoder پاسخی مناسب تولید میکند.
هر Decoder شامل سه بخش اصلی است: Masked Self-Attention (برای جلوگیری از دیدن کلمات آینده هنگام تولید متن)، Attention روی خروجی Encoder (برای تمرکز روی داده ورودی) و یک شبکه Feed Forward.
برای مثال، اگر جمله «I love books» را وارد کنیم و بخواهیم ترجمه فارسی آن ساخته شود، Encoder معنا را درک میکند و Decoder کلمه به کلمه «من کتابها را دوست دارم» تولید میکند. Masked Self-Attention اینجا مهم است چون نباید قبل از زمان مناسب کلمه بعدی را ببیند.
امروزه بسیاری از سایتهای هوش مصنوعی آنلاین و ابزارهای ترجمه ماشینی دقیقاً با استفاده از Decoder میتوانند متنهای طبیعی و دقیق تولید کنند. این بخش را میتوان «مغز خلاق» ترنسفورمر دانست که متن نهایی را میسازد.
آموزش مدل ترنسفورمر (Training) و بهینهسازی آن
آموزش ترنسفورمر فرآیندی پیچیده است که نیازمند دادههای عظیم و قدرت محاسباتی بالاست. در این مرحله، مدل با میلیونها یا حتی میلیاردها جمله تغذیه میشود تا روابط بین کلمات و ساختار زبان را یاد بگیرد. الگوریتم اصلی برای آموزش، Backpropagation و بهینهسازی با روشهایی مانند Adam Optimizer است.
به عنوان مثال، در آموزش مدل GPT، حجم عظیمی از متنهای اینترنتی استفاده شده است. این دادهها به مدل کمک میکنند تا وقتی شما در یک سایت هوش مصنوعی سوالی مینویسید، بتواند پاسخی دقیق و مرتبط ارائه دهد.
در عین حال، آموزش ترنسفورمر هزینه بالایی دارد. به همین دلیل امروزه بسیاری از کاربران به جای آموزش مدل از صفر، از مدلهای از پیش آموزشدیده (Pre-trained Models) استفاده میکنند و آنها را برای کارهای خاص خود تنظیم میکنند (Fine-tuning). این کار باعث شده استفاده از هوش مصنوعی آنلاین برای شرکتها و کاربران عادی بسیار سادهتر و مقرونبهصرفهتر باشد.
تفاوت ترنسفورمر با شبکههای بازگشتی و کانولوشنی
مدلهای بازگشتی (RNN/LSTM) و کانولوشنی (CNN) سالها ابزار اصلی پردازش متن بودند. RNNها دادهها را به ترتیب زمانی پردازش میکردند اما در جملات طولانی دچار فراموشی اطلاعات اولیه میشدند. CNNها هم بیشتر در پردازش تصویر کاربرد داشتند و توان محدودی در فهم زبان داشتند.
ترنسفورمر تفاوت بزرگی ایجاد کرد چون میتواند کل جمله را به صورت موازی پردازش کند. این ویژگی سرعت آموزش را بسیار افزایش داد. همچنین به کمک مکانیزم Self-Attention، وابستگیهای طولانیمدت بین کلمات بهخوبی درک میشوند.
برای مثال، در جمله «دانشآموزانی که دیروز به تهران سفر کردند امروز در کلاس حضور یافتند»، ترنسفورمر میتواند ارتباط «دانشآموزانی» با «حضور یافتند» را درک کند، در حالی که RNN احتمالاً این ارتباط را از دست میدهد.
به همین دلیل امروزه تقریباً همه سایتهای هوش مصنوعی آنلاین به جای معماریهای قدیمی از ترنسفورمر استفاده میکنند. این تحول را میتوان یکی از بزرگترین جهشها در تاریخ هوش مصنوعی AI دانست.
ترنسفورمر و پردازش زبان طبیعی (NLP)
پردازش زبان طبیعی یا NLP یکی از مهمترین شاخههای هوش مصنوعی است و ترنسفورمر انقلابی در این حوزه ایجاد کرده است. وظیفه NLP این است که کامپیوتر بتواند زبان انسان را درک کند و به آن پاسخ دهد.
مدلهای ترنسفورمر مثل BERT و GPT توانستهاند کیفیت کارهایی مثل ترجمه، تولید متن، خلاصهسازی، پاسخگویی به سوالات و حتی تحلیل احساسات را به طرز چشمگیری بهبود دهند. برای مثال، وقتی در یک سایت هوش مصنوعی آنلاین یک مقاله وارد میکنید و میخواهید خلاصهای از آن بگیرید، الگوریتم ترنسفورمر است که پشت صحنه کار میکند.
یکی از مثالهای ساده این است که اگر جمله «امروز هوا بارانی است» داده شود، مدل میتواند احساس منفی یا مثبت پشت جمله را تشخیص دهد. یا اگر سوالی مانند «پایتخت ایران چیست؟» پرسیده شود، مدل به درستی پاسخ «تهران» را برمیگرداند.
این تواناییها باعث شده ترنسفورمر به پرکاربردترین معماری در دنیای هوش مصنوعی AI تبدیل شود.
ترنسفورمر و کاربرد آن در ترجمه ماشینی
یکی از اولین و مهمترین کاربردهای ترنسفورمر در ترجمه ماشینی بوده است. پیش از معرفی ترنسفورمر، ترجمه ماشینی با استفاده از RNN یا LSTM انجام میشد که کیفیت بالایی نداشت. اما با معرفی ترنسفورمر در مقاله «Attention is All You Need»، کیفیت ترجمهها جهش بزرگی پیدا کرد.
به عنوان مثال، اگر جمله انگلیسی «Artificial Intelligence changes the world» را وارد کنید، ترنسفورمر میتواند آن را بهطور دقیق به فارسی ترجمه کند: «هوش مصنوعی جهان را تغییر میدهد». این دقت ناشی از توانایی مدل در درک ارتباط بین واژهها در سطح کل جمله است، نه فقط کلمات مجاور.
امروزه اکثر مترجمهای آنلاین مانند گوگل ترنسلیت از معماری ترنسفورمر استفاده میکنند. این همان چیزی است که باعث شده کیفیت ترجمههای ماشینی نسبت به سالهای گذشته به شکل چشمگیری افزایش یابد.
در نتیجه، وقتی از هوش مصنوعی آنلاین برای ترجمه استفاده میکنید، در واقع در حال استفاده از قدرت ترنسفورمر هستید. همین کاربرد یکی از دلایل اصلی محبوبیت این مدل در میان کاربران و پژوهشگران هوش مصنوعی است.
نقش ترنسفورمر در تولید متن و چتباتها
یکی از برجستهترین کاربردهای مدل ترنسفورمر تولید متن و ساخت چتباتهای هوش مصنوعی است. معماری GPT که بر پایه ترنسفورمر ساخته شده، توانایی دارد متنی روان، منسجم و طبیعی شبیه به انسان تولید کند. این ویژگی باعث شده امروزه بسیاری از سایتهای هوش مصنوعی آنلاین از این فناوری برای پشتیبانی مشتریان یا تولید محتوا استفاده کنند.
برای مثال، وقتی در یک چتبات میپرسید: «مزایای هوش مصنوعی چیست؟»، ترنسفورمر میتواند پاسخی دقیق و کامل بسازد، مثل: «هوش مصنوعی باعث افزایش سرعت پردازش، کاهش هزینهها و بهبود کیفیت تصمیمگیری میشود.» این پاسخها نه از پیش نوشته شدهاند، بلکه به صورت لحظهای توسط مدل ساخته میشوند.
توانایی تولید متن باعث شده ترنسفورمر در حوزههای متنوعی از جمله تولید مقاله، نوشتن ایمیل، تولید داستان و حتی کدنویسی کاربرد داشته باشد. در واقع هر جا که صحبت از «استفاده از هوش مصنوعی» برای تولید متن است، پای ترنسفورمر در میان است.
ترنسفورمر در بینایی ماشین (Computer Vision Transformers – ViT)
ترنسفورمرها فقط در پردازش زبان طبیعی کاربرد ندارند؛ آنها وارد دنیای بینایی ماشین هم شدهاند. مدلهای Vision Transformer (ViT) از همان مکانیزم Attention استفاده میکنند، اما این بار روی بخشهای مختلف یک تصویر تمرکز میکنند.
به عنوان مثال، برای شناسایی یک گربه در تصویر، مدل ViT تصویر را به قطعات کوچک تقسیم میکند (Patch) و سپس هر قطعه را با بقیه مقایسه میکند تا درک کند که مجموعه آنها یک گربه تشکیل میدهند. این رویکرد مشابه کاری است که در متن انجام میدهد؛ یعنی بررسی روابط بین بخشهای مختلف داده.
کاربرد ViT بسیار گسترده است؛ از تشخیص چهره گرفته تا پزشکی (تحلیل تصاویر MRI) و خودروهای خودران. امروز بسیاری از سایتهای هوش مصنوعی AI خدماتی مانند تشخیص تصویر یا شناسایی اشیاء را با کمک ViT ارائه میدهند.
این نشان میدهد که ترنسفورمر یک معماری عمومی است که میتواند نه تنها متن بلکه تصویر و حتی صدا را هم پردازش کند.
معماری BERT و استفاده آن در درک زبان
مدل BERT (Bidirectional Encoder Representations from Transformers) یکی از معروفترین مدلهای مبتنی بر ترنسفورمر است که توسط گوگل در سال ۲۰۱۸ معرفی شد. BERT برخلاف GPT که فقط از Decoder استفاده میکند، مبتنی بر Encoder است و هدف اصلی آن درک بهتر متن است.
BERT جمله را از هر دو جهت (چپ به راست و راست به چپ) تحلیل میکند. برای مثال، اگر جمله «بانک کنار رودخانه بود» را داشته باشیم، BERT میتواند بفهمد که «بانک» به معنی موسسه مالی نیست، بلکه به معنی ساحل رودخانه است. این توانایی درک زمینه باعث شده دقت موتورهای جستجو افزایش چشمگیری پیدا کند.
امروزه موتور جستجوی گوگل برای نمایش نتایج بهتر از معماری BERT استفاده میکند. این یعنی وقتی شما در یک سایت هوش مصنوعی آنلاین یا موتور جستجو عبارتی را مینویسید، در واقع BERT کمک میکند معنای درست درخواست شما فهمیده شود.
معماری GPT و تفاوت آن با BERT
GPT (Generative Pre-trained Transformer) خانوادهای از مدلهای ترنسفورمر است که تمرکز اصلی آن روی تولید متن است. برخلاف BERT که مبتنی بر Encoder است، GPT مبتنی بر Decoder است و به همین دلیل توانایی بالایی در تولید جملههای طبیعی دارد.
تفاوت اصلی این دو مدل در کاربردشان است:
-
BERT برای درک متن عالی است.
-
GPT برای تولید متن طراحی شده است.
برای مثال، اگر از BERT بپرسید: «احساس جملهی (هوا عالی است) چیست؟»، BERT میتواند احساس مثبت را شناسایی کند. اما اگر به GPT بگویید: «یک جمله درباره آینده هوش مصنوعی بنویس»، پاسخ میدهد: «هوش مصنوعی آینده صنعت و آموزش را متحول خواهد کرد.»
این تفاوت باعث شده هر دو مدل در کنار هم در بسیاری از سایتهای هوش مصنوعی استفاده شوند. BERT برای درک سوالات کاربران و GPT برای تولید پاسخهای طبیعی.
از GPT-1 تا GPT-5: تحول مدلهای زبانی بر پایه ترنسفورمر
سفر GPT از نسخه اول تا GPT-5 داستانی شگفتانگیز در دنیای هوش مصنوعی AI است.
-
GPT-1 (2018): اولین نسخه که نشان داد ترنسفورمر میتواند در تولید متن عملکرد خوبی داشته باشد.
-
GPT-2 (2019): جهشی بزرگ که توانست متون طولانی و منسجم تولید کند، اما به دلیل نگرانیهای اخلاقی ابتدا بهطور کامل منتشر نشد.
-
GPT-3 (2020): با 175 میلیارد پارامتر، نقطه عطفی در استفاده گسترده از هوش مصنوعی شد. بسیاری از سایتهای هوش مصنوعی آنلاین خدمات خود را بر اساس این مدل ساختند.
-
GPT-4 (2023): دقت بالاتر، توانایی درک چندزبانه و پاسخهای خلاقانهتر.
-
GPT-5 (2025): آخرین نسخه که ترکیبی از درک عمیقتر، تولید متن پیشرفتهتر و قابلیتهای چندرسانهای است.
این تحولات نشان میدهد ترنسفورمر نهتنها آینده تولید متن، بلکه آینده کل حوزه استفاده از هوش مصنوعی را شکل میدهد.
ترنسفورمر در حوزه گفتار و تشخیص صدا
ترنسفورمرها فقط برای متن و تصویر نیستند؛ آنها در تشخیص گفتار و صدا نیز تحول بزرگی ایجاد کردهاند. مدلهایی مانند Whisper از OpenAI یا wav2vec از فیسبوک، بر پایه ترنسفورمر طراحی شدهاند و توانستهاند کیفیت تبدیل صدا به متن (Speech-to-Text) را به سطحی بیسابقه برسانند.
به عنوان مثال، اگر جمله انگلیسی «Hello, how are you?» با لهجه خاص وارد شود، مدل ترنسفورمر میتواند آن را بهدرستی به متن تبدیل کند و حتی به فارسی ترجمه کند: «سلام، حالت چطور است؟». این دقت برای سیستمهای هوش مصنوعی در تماسهای تلفنی، دستیارهای صوتی و سایتهای هوش مصنوعی آنلاین حیاتی است.
امروزه از این فناوری در اپلیکیشنهای ترجمه زنده صدا، ضبط جلسات و حتی دستیارهای هوشمند مثل Siri و Alexa استفاده میشود. در نتیجه، استفاده از هوش مصنوعی در حوزه گفتار بدون ترنسفورمر عملاً غیرممکن است.
کاربردهای ترنسفورمر در جستجوگرها و موتورهای هوشمند
جستجوگرهای اینترنتی بخش مهمی از زندگی آنلاین ما هستند. معماری ترنسفورمر نقش اساسی در ارتقای کیفیت این جستجوگرها ایفا کرده است. موتورهایی مانند گوگل با استفاده از BERT و مدلهای مشابه توانستهاند درک عمیقتری از زبان کاربران داشته باشند.
به عنوان مثال، اگر شما در گوگل تایپ کنید: «بهترین سایت هوش مصنوعی برای ترجمه رایگان»، موتور جستجو میتواند متوجه شود که تمرکز شما روی ترجمه است نه فقط «سایت هوش مصنوعی». این درک دقیق باعث میشود نتایج مرتبطتر نمایش داده شوند.
علاوه بر گوگل، موتورهای جستجوی اختصاصی در سایتهای هوش مصنوعی آنلاین نیز از ترنسفورمر برای تحلیل سوالات کاربران استفاده میکنند. این یعنی حتی اگر جمله شما مبهم باشد، مدل میتواند منظور اصلی شما را درک کند.
بنابراین، ترنسفورمر کمک کرده جستجوگرها نهتنها کلیدواژهها بلکه معنای واقعی جملات را هم بفهمند.
ترنسفورمر در صنعت: پزشکی، آموزش و تجارت
ترنسفورمرها تنها در حوزه زبان یا جستجو محدود نشدهاند، بلکه در صنایع مختلف نیز کاربرد گستردهای پیدا کردهاند. در پزشکی، مدلهای ترنسفورمر برای تحلیل گزارشهای پزشکی یا تصاویر MRI استفاده میشوند تا تشخیص بیماریها دقیقتر شود. در آموزش، سایتهای هوش مصنوعی آنلاین با کمک ترنسفورمر توانستهاند سامانههای یادگیری هوشمند بسازند که برای هر دانشآموز مسیر آموزشی شخصیسازیشده پیشنهاد میدهند.
در تجارت، ترنسفورمرها برای تحلیل دادههای مشتریان و پیشبینی رفتار آنها به کار میروند. برای مثال، یک فروشگاه آنلاین میتواند با کمک هوش مصنوعی AI حدس بزند کدام محصولات برای شما جذابتر است و همانها را پیشنهاد دهد.
نمونه واقعی این کاربردها را میتوان در پلتفرمهایی مثل آمازون (توصیه محصول)، گوگل هلث (تشخیص بیماری) و سیستمهای آموزشی آنلاین دید. این نشان میدهد که استفاده از هوش مصنوعی بر پایه ترنسفورمر به یک ابزار حیاتی برای پیشرفت صنایع مختلف تبدیل شده است.
مزایا و محدودیتهای مدل ترنسفورمر
ترنسفورمرها مزایای بیشماری دارند. از جمله:
-
توانایی درک وابستگیهای طولانی در متن
-
پردازش موازی و سرعت بالاتر نسبت به RNN
-
کاربرد در متن، تصویر و صدا به طور همزمان
اما این مدلها محدودیتهایی نیز دارند. بزرگترین مشکل، نیاز به منابع محاسباتی عظیم است. برای آموزش مدلهایی مثل GPT-3 یا GPT-4 باید صدها کارت گرافیک قدرتمند بهصورت همزمان کار کنند. همچنین مصرف انرژی بالا و هزینه زیاد یکی دیگر از چالشهای اصلی است.
برای مثال، یک شرکت کوچک بهراحتی نمیتواند از صفر یک مدل ترنسفورمر بزرگ بسازد، بلکه باید از مدلهای آماده در سایتهای هوش مصنوعی آنلاین استفاده کند.
با این حال، مزایای ترنسفورمر بهقدری زیاد است که محدودیتها مانع از گسترش آن نشدهاند. همین حالا تقریباً تمام ابزارهای مدرن هوش مصنوعی AI به نوعی از این مدل استفاده میکنند.
چالشهای محاسباتی و منابع سختافزاری مورد نیاز
یکی از بزرگترین موانع در مسیر استفاده گسترده از ترنسفورمرها، هزینه بالای محاسباتی آنهاست. این مدلها برای آموزش به میلیاردها پارامتر نیاز دارند و همین موضوع باعث میشود مصرف انرژی و منابع سختافزاری بسیار بالا برود.
برای مثال، آموزش GPT-3 به هزاران GPU قدرتمند و چندین هفته زمان نیاز داشت. این یعنی تنها شرکتهای بزرگ فناوری قادر به آموزش چنین مدلهایی هستند. شرکتهای کوچکتر معمولاً مجبورند از نسخههای آماده در سایتهای هوش مصنوعی آنلاین بهره ببرند.
علاوه بر هزینه سختافزاری، نگهداری این مدلها نیز دشوار است. اجرای یک مدل ترنسفورمر بزرگ در زمان واقعی (Real-time) به حافظه و پردازنده قوی نیاز دارد. به همین دلیل، بسیاری از سرویسهای هوش مصنوعی آنلاین مبتنی بر فضای ابری (Cloud) ارائه میشوند.
این چالشها باعث شده پژوهشگران به دنبال روشهایی برای فشردهسازی و بهینهسازی مدلها باشند تا استفاده از هوش مصنوعی برای همه در دسترستر شود.

تکنیکهای بهینهسازی و فشردهسازی مدلهای ترنسفورمر
با توجه به اینکه مدلهای ترنسفورمر بسیار بزرگ و پرهزینه هستند، پژوهشگران روشهایی برای بهینهسازی و فشردهسازی آنها ارائه کردهاند. این تکنیکها کمک میکنند تا بدون کاهش شدید کیفیت، سرعت اجرا افزایش یابد و منابع سختافزاری کمتری مصرف شود.
از مهمترین روشها میتوان به Pruning (حذف پارامترهای غیرضروری)، Quantization (کاهش دقت اعداد برای کاهش حجم حافظه) و Knowledge Distillation (انتقال دانش از یک مدل بزرگ به مدل کوچکتر) اشاره کرد.
برای مثال، نسخههای سبکتر BERT مانند DistilBERT ساخته شدهاند که با داشتن پارامترهای کمتر، سرعت بیشتری دارند و در موبایل یا مرورگرهای وب نیز قابل اجرا هستند. این بهینهسازیها امکان استفاده از هوش مصنوعی آنلاین را برای کاربران عادی فراهم کردهاند.
به همین دلیل، امروز حتی روی گوشیهای هوشمند هم میتوان از سایتهای هوش مصنوعی برای ترجمه، چت یا پردازش متن استفاده کرد. این تکنیکها آینده دسترسپذیری هوش مصنوعی AI را تضمین میکنند.
آینده مدلهای ترنسفورمر و تاثیر آن بر هوش مصنوعی
ترنسفورمرها تاکنون تحولی عظیم ایجاد کردهاند، اما آینده آنها حتی درخشانتر خواهد بود. انتظار میرود نسخههای آینده این مدلها بتوانند دادههای چندرسانهای (متن، تصویر، صدا و ویدئو) را همزمان پردازش کنند.
برای مثال، یک سایت هوش مصنوعی آنلاین در آینده میتواند ویدئوی آموزشی شما را ببیند، محتوای آن را خلاصه کند و حتی به چند زبان ترجمه نماید. این یعنی مرز بین انسان و ماشین روزبهروز کمتر خواهد شد.
همچنین انتظار میرود مدلهای ترنسفورمر آینده با مصرف انرژی کمتر و سرعت بیشتر عمل کنند. پژوهشگران به دنبال مدلهایی هستند که هم قدرتمند باشند و هم روی سختافزارهای معمولی قابل استفاده باشند.
به همین دلیل، آینده استفاده از هوش مصنوعی به شدت وابسته به ترنسفورمر است. بسیاری از متخصصان معتقدند که این معماری همچنان محور اصلی توسعه هوش مصنوعی AI در سالهای آینده خواهد بود.
چرا ترنسفورمرها در ایران هم محبوب شدهاند؟
محبوبیت ترنسفورمرها در ایران دلایل متعددی دارد. نخست اینکه بسیاری از ابزارهای جهانی مثل گوگل ترنسلیت، ChatGPT و موتورهای جستجو همگی بر پایه این مدل ساخته شدهاند. کاربران ایرانی هم برای ترجمه، تولید متن یا حتی آموزش زبان به این سرویسها نیاز دارند.
دوم اینکه بسیاری از سایتهای هوش مصنوعی ایرانی خدمات متنوعی مثل ترجمه متن، تولید مقاله یا خلاصهسازی محتوا را ارائه میدهند. این سرویسها معمولاً با نسخههای بهینهشده مدلهای ترنسفورمر کار میکنند.
برای مثال، یک دانشجو در ایران میتواند متن انگلیسی پایاننامهاش را وارد یک ابزار هوش مصنوعی آنلاین کند و در چند ثانیه ترجمه فارسی آن را دریافت کند. یا یک کسبوکار ایرانی میتواند با کمک ترنسفورمر محتوای تبلیغاتی تولید کند.
بنابراین، ترنسفورمرها در ایران نهتنها برای سرگرمی بلکه برای آموزش، تحقیق و تجارت نیز پرکاربرد شدهاند. این محبوبیت روزبهروز در حال افزایش است.
بهترین منابع آموزشی برای یادگیری مدل ترنسفورمر
برای کسانی که میخواهند وارد دنیای ترنسفورمرها شوند، منابع آموزشی متنوعی وجود دارد. از دورههای آنلاین گرفته تا مستندات رسمی و مقالات علمی.
-
مقاله اصلی گوگل با عنوان Attention is All You Need نقطه شروع خوبی است.
-
دورههای آنلاین سایتهایی مثل Coursera، Udemy و DeepLearning.AI آموزشهای عملی در زمینه ترنسفورمر ارائه میدهند.
-
کتابها و مقالات آموزشی نیز به زبان ساده مفاهیم Encoder، Decoder و Attention را توضیح میدهند.
برای علاقهمندان ایرانی، مطالعه آموزشهای موجود در سایتهای هوش مصنوعی آنلاین به زبان فارسی نیز کمک بزرگی است. به عنوان مثال، برخی سایتها آموزش استفاده از BERT یا GPT در پروژههای واقعی را مرحلهبهمرحله توضیح دادهاند.
این منابع باعث میشوند حتی افرادی که تازه وارد حوزه هوش مصنوعی AI شدهاند، بتوانند از پایه تا پیشرفته ترنسفورمر را یاد بگیرند و در پروژههای خود بهکار گیرند.
جمعبندی
مدل ترنسفورمر بدون شک انقلابی در دنیای هوش مصنوعی ایجاد کرده است. این معماری توانست ضعفهای شبکههای قدیمی مانند RNN و LSTM را رفع کند و امروز در ترجمه ماشینی، تولید متن، تشخیص صدا، بینایی ماشین و حتی موتورهای جستجو نقشی کلیدی ایفا میکند.
از GPT گرفته تا BERT، همه این مدلهای مشهور بر پایه ترنسفورمر ساخته شدهاند و همین نشان میدهد که آینده استفاده از هوش مصنوعی آنلاین به این معماری وابسته است.
اگرچه چالشهایی مانند هزینه بالای محاسباتی وجود دارد، اما با تکنیکهای بهینهسازی، این مشکلات تا حد زیادی رفع خواهند شد. در پاسخ به پرسش «آیا ترنسفورمر آینده هوش مصنوعی است؟»، میتوان با اطمینان گفت: بله، ترنسفورمر نه فقط آینده بلکه حال حاضر هوش مصنوعی AI است.
سوالات متداول
مقالات مشابه

برنامه نویسی با هوش مصنوعی
1404/10/14
18 دقیقه

رشته هوش مصنوعی
1404/10/09
18 دقیقه

ایمیل مارکتینگ با هوش مصنوعی
1404/10/07
23 دقیقه

بازار کار هوش مصنوعی
1404/09/30
18 دقیقه

google colab چیست؟
1404/09/27
18 دقیقه
ساخت بازی کامپیوتری با هوش مصنوعی
1404/09/25
14 دقیقه

تولید محتوا با هوش مصنوعی
1404/09/23
25 دقیقه

آشنایی با ابزارهای هوش مصنوعی Google Cloud AI
1404/09/18
24 دقیقه

راهنمای جامع و کاربردی هوش مصنوعی و تحلیل رقبا
1404/09/11
17 دقیقه

آشنایی با ابزارهای هوش مصنوعی Metabase
1404/09/09
17 دقیقه

هوش مصنوعی با MATLAB: از تحلیل داده تا ساخت مدلهای پیشرفته
1404/09/06
25 دقیقه
دانلود اپلیکیشن
ارتقا سطح دانش و مهارت و کیفیت سبک زندگی با استفاده از هوش مصنوعی یک فرصت استثنایی برای انسان هاست.
ثبت دیدگاه
نظری موجود نمیباشد