یادگیری تقویتی (Reinforcement Learning) چیست؟

اگر اهل بازیهای کامپیوتری باشید، حتما میدانید که یک بازیکن تازهکار بارها شکست میخورد تا بالاخره یاد بگیرد چطور به مرحله بعد برسد. هر بار که اشتباه میکند، تجربهای جدید به دست میآورد و وقتی درست عمل میکند، پاداشش رسیدن به امتیاز یا مرحله بالاتر است. این ایده دقیقا قلب پاسخ به سوال یادگیری تقویتی (Reinforcement Learning – RL) چیست را هدف قرار میدهد.
یادگیری تقویتی یکی از شاخههای مهم یادگیری ماشین است که به سیستمها اجازه میدهد مثل انسان یا حیوانات، از طریق آزمون و خطا و دریافت پاداش یا تنبیه، مهارتهای جدید یاد بگیرند. تفاوت اصلی RL با روشهای دیگر در این است که نیازی به دادههای برچسبخورده مثل یادگیری با ناظر ندارد، بلکه خودش در تعامل با محیط تجربه جمع میکند.
به زبان ساده، میتوان RL را یادگیری از تجربه و پیامد تصمیمها دانست. همین ویژگی باعث شده این روش به یکی از پرکاربردترین ابزارها برای توسعه رباتهای هوشمند، ماشینهای خودران و حتی قهرمانان دنیای بازیهای رایانهای تبدیل شود. قرار است این الگوریتم را در این مقاله کاملا یاد بگیرد، پس تا انتهای این مطلب را بخوانید.
شناخت و درک اولیه از یادگیری تقویتی
یادگیری تقویتی یا Reinforcement Learning (RL) یکی از شاخههای مهم هوش مصنوعی و یادگیری ماشین است که به کمک آن، یک عامل هوشمند (Agent) یاد میگیرد چگونه در یک محیط تصمیمگیری کند.
در این روش، عامل مثل یک بازیگر در یک محیط قرار دارد و با انجام عملها (Actions) و دریافت پاداش (Reward) یا جریمه (Penalty)، یاد میگیرد بهترین راه را برای رسیدن به هدف پیدا کند. مثلا در یک بازی رایانهای، بازیکن با گرفتن ستاره پاداش میگیرد و اگر اشتباه کند، ممکن با از دست دادن جان جریمه میشود.
یادگیری تقویتی با یادگیری نظارتشده که نیاز به دادههای برچسبدار دارد (مثل تشخیص عکس گربه) و یادگیری بدون ناظر که الگوهای پنهان را پیدا میکند (مثل گروهبندی آهنگهای اسپاتیفای) فرق دارد.
در یادگیری تقویتی، هیچ معلم یا برچسبی نیست. مدل خودش از اشتباهاتش یاد میگیرد. اگر این مدل را به یک مثال انسانی تبدیل کنیم؛ مثل وقتی است که دوچرخهسواری را امتحان میکنید. شما تا زمانیکه کامل آن را یاد بگیرید، ممکن است بارها زمین بخورید.
یادگیری تقویتی در سال 2025 در جاهای زیادی مثل رباتهایی که یاد میگیرند راه بروند یا اپلیکیشنهایی که مسیر بهتری در نقشه پیشنهاد میدهند، استفاده میشود. این روش به ماشینها کمک میکند تا مثل انسانها یاد بگیرند. همچنین از آن در زمینههای مختلفی مثل رباتیک، بازیهای کامپیوتری، خودروهای خودران و حتی بهینهسازی منابع استفاده میشود. در حال حاضر میتوان گفت یادگیری تقویتی یکی از هیجانانگیزترین بخشهای هوش مصنوعی به حساب میآید.
تاریخچه یادگیری تقویتی؛ راهی برای تربیت هوش مصنوعی
یادگیری تقویتی ریشه در تلاشهای اولیه برای مدلسازی رفتارهای هوشمند دارد. بر اساس این فناوری از دهه 1950 با الهام از روانشناسی رفتارگرایی آغاز شد. رفتارگرایی که به موجودات زنده طریق پاداش و جریمه آموزش میدهد، مبنایی شد برای آموزش به ماشین تا بیشتر و بیشتر انسانی رفتار کند. برای مثال، محققان اولیه سعی کردند ماشینهایی بسازند که مانند حیوانات، با آزمونوخطا رفتارهایی مانند یافتن غذا را یاد بگیرند.
در دهه 1980، مفهوم یادگیری تقویتی با معرفی الگوریتمهای اولیه مانند یادگیری زمانی-تفاضلی (Temporal-Difference Learning) شکل گرفت. این روش به ماشینها اجازه داد تا با پیشبینی پاداشهای آینده، تصمیمهای بهتری بگیرند، مانند یک برنامه که یاد میگیرد در بازی سادهای مانند دوز برنده شود.

شروع تغییرات یادگیری تقویتی
در دهه 1990، پیشرفتهای مهمی رخ داد. الگوریتم Q-learning، که در کتاب Sutton & Barto توضیح داده شده، به ماشینها کمک کرد تا بدون نیاز به مدل کامل محیط، بهترین اقدامات را انتخاب کنند.
برای مثال، Q-learning به یک ربات مسیریاب کمک میکند تا در اپلیکیشنهای نقشهیابی، بهترین مسیر را پیدا کند. با پیشرفت و بهبود قدرت محاسباتی در قرن بیستویکم، یادگیری تقویتی با یادگیری عمیق ترکیب شد و الگوریتمهایی مانند Deep Q-Networks (DQN) معرفی شدند. این پیشرفت به ماشینها اجازه داد تا وظایف پیچیدهتری انجام دهند.
با این پیشرفت یکی از نقاط عطف کلیدی در سال 2016 رخ داد، زمانی که برنامه AlphaGo از شرکت DeepMind توانست با استفاده از یادگیری تقویتی، قهرمان جهان لی سدول را در بازی گو (GO) شکست دهد. این برنامه با آزمونوخطا یاد گرفت تا استراتژیهای پیچیدهای را اجرا کند. در سالهای اخیر، یادگیری تقویتی در رباتیک و سیستمهای خودکار، مانند رباتهای تحویلدهنده که مسیرهای بهینه را یاد میگیرند، گسترش یافته است.
ساز و کار یادگیری تقویتی
بچهای را فرض کنید که در حال یادگیری دوچرخهسواری است. او هیچ کتاب آموزشیای نخواهد خواند. کسی هم تمام جزئیات را برایش توضیح نمیدهد. پس تنها راه یادگیریاش چیست؟ بله، امتحان کردن. اگر خوب رکاب بزند و تعادلش را حفظ کند، زمین نمیخورد؛ یعنی پاداش. در مقابل اگر اشتباه کند، زمین میافتد و دردش میگیرد؛ یعنی تنبیه. همین آزمون و خطا به مرور باعث میشود کودک بفهمد چه حرکاتی درست و چه حرکاتی اشتباه است.
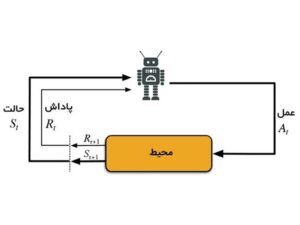
یادگیری تقویتی دقیقا همین فرایند را برای ماشینها شبیهسازی میکند. در این روش، یک عامل (Agent) در یک محیط (Environment) فعالیت میکند. عامل بر اساس اقدام (Action) تصمیم میگیرد، محیط نتیجه را برمیگرداند و در قالب پاداش (Reward) یا تنبیه (Penalty) به او بازخورد میدهد. ساختار ساده RL به شکل زیر است.
- عامل (Agent): همان یادگیرنده یا ماشین.
- محیط (Environment): جایی که عامل در آن عمل میکند؛ مثل یک بازی یا خیابان برای ماشین خودران.
- اقدامها (Actions): انتخابهایی که عامل میتواند انجام دهد.
پاداشها (Rewards): امتیاز مثبت یا منفی که به عامل برمیگردد.
به این ترتیب، عامل یاد میگیرد تصمیمهایی بگیرد که در طول زمان بیشترین پاداش را برایش داشته باشند.
یادگیری تقویتی چطور کار میکند؟
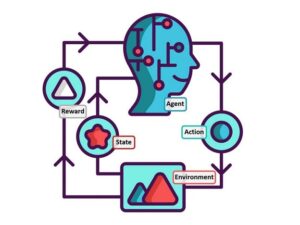
یادگیری تقویتی در واقع یک چرخه مداوم است که عامل (Agent) از طریق تجربههایش یاد میگیرد. این چرخه چهار مرحله اصلی دارد:
- مشاهده وضعیت (State): عامل ابتدا موقعیت فعلی خود را در محیط میبیند. مثل رباتی که در ابتدای یک ماز قرار دارد و موقعیتش مشخص است.
- انتخاب اقدام (Action): بر اساس آنچه تاکنون یاد گرفته، عامل تصمیم میگیرد چه کاری انجام دهد، مانند حرکت به جلو یا چرخش.
- دریافت بازخورد (Reward): محیط واکنش نشان میدهد و پاداش یا تنبیهی به عامل میدهد. مثلاً ربات اگر به دیوار برخورد کند، پاداش منفی میگیرد، اگر به مسیر درست برود، پاداش مثبت.
- بهروزرسانی دانش: عامل تجربه جدید را با تجربههای قبلی ترکیب کرده و استراتژیاش را اصلاح میکند تا دفعه بعد تصمیم بهتری بگیرد.
این چرخه تا زمانی ادامه پیدا میکند که عامل بهینهترین راه رسیدن به هدف را یاد بگیرد. نکته کلیدی در RL این است که پاداشها ممکن است فوری نباشند. گاهی عامل باید تصمیمهای کوچک متعددی بگیرد تا در پایان پاداش بزرگ دریافت کند. این مفهوم به نام بازده تجمعی (Cumulative Reward) شناخته میشود.
الگوریتمها و روشهای پرکاربرد در یادگیری تقویتی
یادگیری تقویتی از چند الگوریتم معروف برای یادگیری بهترین استراتژی استفاده میکند. این الگوریتمها بسته به نحوه یادگیری و تعامل با محیط، دستهبندی میشوند.
- Q-Learning (بدون مدل / Model-free): در این مدل عامل یاد میگیرد برای هر وضعیت و اقدام، چه مقدار پاداش انتظار دارد. این الگوریتم نیازی به مدل محیط ندارد و تنها تجربهها را ثبت و بهروزرسانی میکند.
- SARSA (State-Action-Reward-State-Action): مشابه Q-Learning است، اما به جای یادگیری بهترین اقدام ممکن، از اقدام واقعیای که انجام داده، یاد میگیرد که باعث میشود یادگیری محافظهکارانهتر و کمریسکتر باشد.
- Deep Q-Networks (DQN): ترکیبی از Q-Learning و شبکههای عصبی عمیق است. به عامل اجازه میدهد در محیطهای بسیار پیچیده با تعداد زیادی وضعیت و اقدام، یادگیری کند.
- Policy Gradient و Actor-Critic: این روشها به جای یادگیری مقدار پاداش، مستقیما سیاست تصمیمگیری عامل را یاد میگیرند و برای محیطهای با فضای بزرگ و پیچیده مناسباند.
این الگوریتمها ابزارهای اصلی یادگیری تقویتی هستند و بسته به پیچیدگی محیط و هدف یادگیری، یکی از آنها انتخاب میشود.
ابزارهای یادگیری تقویتی
در پاسخ به پرسش یادگیری تقویتی چیست؟ باید ابزارهای آن را نیز بشناسید. RL به ابزارهای نرمافزاری نیاز دارد که به برنامهنویسان کمک میکنند تا الگوریتمهای آن را پیادهسازی کنند. این ابزارها مانند جعبهابزارهایی هستند که به ماشینها امکان یادگیری از آزمونوخطا را میدهند، مانند آموزش یک ربات مجازی تا بتوانید در یک بازی ساده مانند Flappy Bird حرکت کند. ابزارهای کلیدی یادگیری تقویتی در زیر معرفی شدهاند.
- OpenAI Gym: یک کتابخانه رایگان که محیطهای شبیهسازیشده مانند بازیهای ویدیویی را ارائه میدهد. برای مثال، شما میتوانید از Gym برای آموزش یک ربات استفاده کنید تا یاد بگیرد چگونه در یک مسیر مجازی حرکت کند.
- Stable-Baselines3: مجموعهای از الگوریتمهای آماده که پیادهسازی یادگیری تقویتی را آسان میکند. به طور مثال با این ابزار میتوانید به یک برنامه یاد دهید تا در بازی شطرنج حرکتهای بهتری انتخاب کند.
- TensorFlow و PyTorch: کتابخانههای پیشرفته برای ساخت مدلهای پیچیدهتر یادگیری تقویتی. برای نمونه، PyTorch به رباتهای صنعتی کمک میکند تا یاد بگیرند چگونه اشیا را با دقت جابهجا کنند.
- RLlib: یک پلتفرم قدرتمند برای پروژههای بزرگ که در صنایع استفاده میشود. مانند سیستمهای آمازون برای بهینهسازی مسیر رباتهای تحویل انبار.
این ابزارها با پشتیبانی از زیرساختهای محاسباتی مانند سرورهای ابری، یادگیری تقویتی را در دسترستر کردهاند.
یادگیری تقویتی در دنیای واقعی دهه اخیر
یادگیری تقویتی در دنیای واقعی کاربردهای گستردهای دارد، بهطوری که بسیاری از فناوریهای پیشرفته امروز بدون آن امکانپذیر نبودند.
- بازیهای کامپیوتری و هوش مصنوعی بازیها: سیستمهایی مانند AlphaGo با RL یاد گرفتند چگونه در شطرنج و بازیهای تختهای، تصمیمات بهینه بگیرند، حتی بدون اینکه از انسانها داده برچسبخورده داشته باشند.
- رباتیک و ماشینهای خودران: رباتها با آزمون و خطا و دریافت پاداش، مهارتهای حرکتی و مسیریابی خود را بهبود میدهند. ماشینهای خودران نیز با RL یاد میگیرند چگونه در خیابانها تصمیمگیری کنند و خطر تصادف را کاهش دهند.
- بهینهسازی منابع: RL در مدیریت انرژی ساختمانها، شبکههای برق و اینترنت به کار میرود تا مصرف منابع بهینه شود و هزینهها کاهش یابد.
- سیستمهای توصیهگر و تجارت: فروشگاهها و سرویسهای آنلاین از RL برای پیشنهاد محصولاتی که بیشترین احتمال خرید را دارند استفاده میکنند.
هر کدام از این مثالها نشان میدهند که RL چگونه به سیستمها اجازه میدهد از تجربه خود یاد بگیرند و به مرور تصمیمات بهتری بگیرند، بدون اینکه برای هر وضعیت مشخص، داده برچسبخورده داشته باشند.

مزایایی که یادگیری تقویتی دارد
یادگیری تقویتی به دلیل تواناییاش در آموزش ماشینها از طریق آزمونوخطا، نقاط قوت فراوانی دارد که در زیر ذکر شدهاند.
- یادگیری از تجربه: عامل نیازی به دادههای برچسبخورده ندارد و خودش از تعامل با محیط میآموزد. برخلاف یادگیری با ناظر، این روش نیازی به دادههای آماده ندارد. برای مثال، یک برنامه میتواند در بازی ویدیویی مانند Pac-Man با امتحان کردن حرکتها، بهترین استراتژی را یاد بگیرد.
- انعطافپذیری: این روش قابلیت یادگیری در محیطهای پویا و تغییرپذیر را دارد. در حوزههای متنوعی مانند بازیها، رباتیک و حتی بهینهسازی تبلیغات در شبکههای اجتماعی مانند یوتیوب کاربرد دارد.
- حل مسائل پیچیده: یادگیری تقویتی در محیطهای پویا، مانند رباتهایی که در انبارها مسیر بهینه را پیدا میکنند، بسیار موثر است. در واقع این مدل توانایی یافتن بهترین استراتژی حتی در فضاهای بزرگ و پیچیده.
این روش به ماشینها امکان میدهد تا در موقعیتهای پیچیده تصمیمهای هوشمند بگیرند، مانند یادگیری حرکتهای حرفهای در یک بازی شطرنج بدون نیاز به دستورالعملهای دقیق.
محدودیتهای یادگیری تقویتی
یادگیری تقویتی، با وجود پتانسیلهای بالای آن در بهبود تصمیمگیریهای خودکار، با چالشهای عمدهای روبهرو است.
- پیچیدگی محاسباتی: آموزش مدلها به زمان و قدرت محاسباتی زیادی نیاز دارد. به طور مثال آموزش یک ربات برای راه رفتن ممکن است روزها طول بکشد، زیرا باید هزاران بار آزمونوخطا کند.
- طراحی پاداش دشوار: اگر پاداشها بهدرستی تنظیم نشوند، ماشین ممکن است رفتارهای اشتباه یاد بگیرد. برای مثال، یک برنامه در بازی اگر پاداشها گمراهکننده باشند، فقط دور خودش میچرخد.
- نیاز به محیطهای شبیهسازیشده: یادگیری تقویتی اغلب به محیطهای مجازی نیاز دارد. مثلا، آموزش یک خودروی خودران در دنیای واقعی خطرناک است و نیاز به شبیهسازی دارد.
- تعادل بین کاوش و بهرهبرداری: عامل باید تصمیم بگیرد که چه زمانی روشهای جدید را امتحان کند و چه زمانی از تجربههای قبلی استفاده نماید.
بنابراین، موفقیت در یادگیری تقویتی مستلزم ترکیبی از منابع محاسباتی مناسب، طراحی پاداش هوشمند و استفاده از محیطهای امن شبیهسازی است. این موارد برای توسعه و ارزیابی مدلها الزامی است تا از رفتارهای ناخواسته جلوگیری شود و مدلهای کارآمدتر به دست آیند.

آینده پیش روی یادگیری تقویتی
یادگیری تقویتی روزبهروز در حال پیشرفت است و کاربردهای آن فراتر از رباتیک و بازیها میرود. ترکیب RL با شبکههای عصبی عمیق (Deep RL) باعث شده سیستمها در محیطهای بسیار پیچیده و با ابعاد زیاد هم یاد بگیرند.
از دیگر روندهای نوین میتوان به یادگیری تقویتی چندعاملی (Multi-agent RL) اشاره کرد که در آن چند عامل به صورت همزمان در یک محیط یاد میگیرند و تعاملات پیچیده را مدیریت میکنند. این روش برای شبیهسازی جمعیت، ترافیک یا اقتصاد کاربرد دارد.
همچنین تلاشها برای کاهش هزینه آموزش و بهبود تعمیمپذیری ادامه دارد تا RL بتواند در مسائل واقعی و محیطهای غیرقابل پیشبینی به راحتی استفاده شود.
در این پیشرفتها میتوان به یکی از روندهای اصلی RL در سال 2025 اشاره کرد که ادغام یادگیری تقویتی با فناوریهای نوظهور مانند اینترنت اشیا (IoT) است. برای نمونه، سیستمهای هوشمند در شهرها میتوانند از یادگیری تقویتی برای مدیریت چراغهای راهنمایی استفاده کنند تا ترافیک کاهش یابد.
علاوهبر آن الگوریتمهای پیشرفتهتر مانند Proximal Policy Optimization (PPO) و ترکیب آنها با یادگیری عمیق، به ماشینها کمک میکنند تا وظایف پیچیدهتری را سریعتر یاد بگیرند. به طور مثال رباتهای جراحی میتوانند با این روش دقت بیشتری در عملهای پزشکی داشته باشند.
با این حال، چالشهایی مانند نیاز به منابع محاسباتی بالا و طراحی پاداشهای دقیق همچنان وجود دارند. محققان در حال توسعه روشهایی مانند یادگیری تقویتی چندعاملی هستند تا چندین ماشین با هم همکاری کنند.
تا سال 2030، انتظار میرود یادگیری تقویتی در حوزههای بیشتری مانند انرژیهای تجدیدپذیر و امنیت سایبری نفوذ کند. این فناوری در حال شکلدهی به آیندهای هوشمندتر است. به زبان ساده، آینده RL روشن است: سیستمها نهتنها یاد میگیرند، بلکه میتوانند با هم همکاری کنند و راهحلهای خلاقانه برای مشکلات پیچیده ارائه دهند.
جمع بندی؛ پاسخ نهایی یادگیری تقویتی چیست؟
یادگیری تقویتی به شما نشان میدهد که ماشینها میتوانند مثل انسانها از تجربه یاد بگیرند: با آزمون و خطا، دریافت پاداش و اصلاح رفتار. این روش نهتنها در بازیها و رباتیک، بلکه در بهینهسازی منابع، ماشینهای خودران و سیستمهای توصیهگر کاربرد دارد.
پس تا اینجا کاملا درک کردید که یادگیری تقویتی چیست؟ حالا حتی با دانش ابتدایی میتوانید با محیطهای شبیهسازی شده مانند OpenAI Gym یا پروژههای ساده پایتون، شروع کنید و تجربه کنید که چگونه یک عامل هوشمند میآموزد تصمیمات بهینه بگیرد. هر قدم عملی باعث میشود درک شما از RL عمیقتر و ملموستر شود
چکیده
یادگیری تقویتی (Reinforcement Learning) شاخهای از هوش مصنوعی است که به سیستمها امکان میدهد با آزمون و خطا و دریافت پاداش یا تنبیه، مهارتهای جدید یاد بگیرند. برخلاف یادگیری با ناظر، در RL عامل خودش تجربه جمع میکند و بهترین استراتژی را پیدا میکند. این روش در بازیهای کامپیوتری، رباتیک، خودروهای خودران و بهینهسازی منابع کاربرد دارد. با الگوریتمهایی مانند Q-Learning، DQN و Policy Gradient، سیستمها قادرند در محیطهای پیچیده و پویا تصمیمگیری کنند. RL نهتنها باعث پیشرفت فناوری میشود بلکه فرصتی عالی برای دانشجویان و علاقهمندان است تا با پروژههای عملی، مهارتهای خود را تقویت کنند.
سوالات متداول
مقالات مشابه

برنامه نویسی با هوش مصنوعی
1404/10/14
18 دقیقه

رشته هوش مصنوعی
1404/10/09
18 دقیقه

ایمیل مارکتینگ با هوش مصنوعی
1404/10/07
23 دقیقه

بازار کار هوش مصنوعی
1404/09/30
18 دقیقه

google colab چیست؟
1404/09/27
18 دقیقه
ساخت بازی کامپیوتری با هوش مصنوعی
1404/09/25
14 دقیقه

تولید محتوا با هوش مصنوعی
1404/09/23
25 دقیقه

آشنایی با ابزارهای هوش مصنوعی Google Cloud AI
1404/09/18
24 دقیقه

راهنمای جامع و کاربردی هوش مصنوعی و تحلیل رقبا
1404/09/11
17 دقیقه

آشنایی با ابزارهای هوش مصنوعی Metabase
1404/09/09
17 دقیقه

هوش مصنوعی با MATLAB: از تحلیل داده تا ساخت مدلهای پیشرفته
1404/09/06
25 دقیقه
دانلود اپلیکیشن
ارتقا سطح دانش و مهارت و کیفیت سبک زندگی با استفاده از هوش مصنوعی یک فرصت استثنایی برای انسان هاست.
ثبت دیدگاه
نظری موجود نمیباشد